公共背景噪聲下激活式的聲紋密碼安全控制方法及系統與流程
2023-10-31 12:40:32 3
本發明涉及智能家居的人機互動技術領域,尤其涉及一種公共背景噪聲下激活式的聲紋密碼安全控制方法及系統。
背景技術:
隨著社會的發展,語音作為一種媒介出現在人機互動界面中,是社會發展的趨勢,相比其它任何一種人與人之間的交流方式來說,語音交流是一種快速的手段,語音識別已經慢慢滲透於我們日常生活當中,現在很多行業先驅相信借於語音進行人機之間的交互,會引向一個方便人們日常生活。
自動語音識別(automaticspeechrecognition,asr)技術自從二十世紀五十年代以來一直研究的主題。自動語音識別技術是一種將人的語音轉換為文本的技術。語音識別是一個多學科交叉的領域,它與聲學、語音學、語言學、數位訊號處理理論、資訊理論、計算機科學等眾多學科緊密相連。由於語音信號的多樣性和複雜性,語音識別系統在人機互動領域的應用還不是很成熟,只有在特定的條件下獲得滿意的性能,或者說只能應用於特定的某些場合。
在智能家居給人們帶來便捷生活的同時,人們的控制習慣漸漸發生了改變。語音技術的發展也為控制入口做出了一個很好的補充,再拋去傳統遙控器和手機app之後,通過語音指令的發送讓人們的生活更加便利。所謂智能語音主要是通過語音識別技術和語音合成技術為用戶提供各種服務。在語音控制技術方面,人們與機器進行語音交流,讓機器明白你說什麼,這是人們長期以來夢寐以求的事情。試音識別技術就是讓機器通過識別和理解過程把語音信號轉變為相應的文本或命令的技術。
就目前語音識別的發展狀況,語音識別技術分為很多種模式,比如說按系統的用戶情況分為特定人和非特定人識別系統,按系統的詞彙量分為小詞彙量、中詞彙量和大詞彙量系統,按語音的輸入方式分為孤立詞、連接詞和連續語音系統等,按輸入語音的發音方式分朗讀式、口語式,按輸入語音的方言背景情況分為普通話、方言背景普通話、方言語音識別系統,按輸入語言的情感狀態分為中性語音、情感語音識別系統等等。但在高識別率的情況下只有通過特定的條件下才能實現。
現在設備的人機互動界面有鍵盤、圖像、指紋等方式,但是鍵盤操作有很多不方便。在特定環境下,比如汽車駕駛人員在駕駛的時候操作鍵盤要手眼並用,就無法注意到路面狀況,這就存在著交通隱患。對於某些身體殘疾或老人來說,界面式的操作都不是很方便,甚至是不可能的。
通信以及網絡的全球覆蓋使得信息公開化成為歷史必然,人們獲取資料的手段前所未有的豐富,然而負面影響也隨之而來。伴隨著信息透明化,個人隱私的安全性也受到了極大的威脅,相應的,如何正確進行個人身份的識別進而保護私人數據,是人機互動中一個亟待深入的課題。在個人身份識別中,傳統的文字密碼等保密手段存在著易被竊取和冒認的危險,而利用人本身的生物特徵是相對比較可靠的一門技術。許多生物特徵往往具有唯一性,如dna、虹膜、指紋等等,這些特徵不會改變;另一方面就是聲音在一定的時間間隔內相對穩定的特徵。上述兩方面都可以作為識別的依據。聲紋密碼識別相對於指紋、虹膜識別來說,人聲的採集成本低廉、操作簡便,具有很好的通用性和獨特性;同時聲音帶有較強的個人特徵,可以廣泛地普及到人們的日常生活領域中。
對於現狀的智能家居的語音控制在很多場景下因語音交互體驗不如人意而深受詬病,究其主要原因是受限於空間距離、背景噪聲、其他人聲的幹擾、回聲、混響等多重複雜因素,進而出現識別距離近、識別率低、安全性能低的明顯缺點。現在大部分智能家居系統中的語音控制只是做到簡單的控制,忽略了其功效和安全性。
所以說在人機互動中的自然語言交互的公共背景噪聲下聲音拾取和安全性是兩個亟待深入研究的兩個課題。
技術實現要素:
為了克服現有技術存在的缺點與不足,本發明提供一直公共背景噪聲下激活式的聲紋密碼安全控制方法及系統,解決了背景噪聲,其他人聲、回聲、混響低信噪比下對語音突發的增量進行定位拾取,通過三次安全語音識別及控制的操作解決上述現狀的問題。
為解決上述技術問題,本發明提供如下技術方案:一種公共背景噪聲下激活式的聲紋密碼安全控制方法,包括下述步驟:
s1、激活識別模塊在普通環境下實時進行語音信號監測,若檢測到語音信號,則對語音信號進行預加重、加窗和分幀處理,並求取語音信號的幅度值;根據實驗得到語音信號與噪聲之間的信噪比,並將信噪比轉化為幅度差t;設t為判決門限值,若語音信號的前一幀與後一幀只差大於等於t,則認為進入靜默期;若語音信號的前一幀與後一幀只差小於t,則判斷是激活標誌,並激活聲源定位拾取模塊;
s2、聲源定位拾取模塊通過麥克風陣列接收交互目標聲源數據,並對交互目標聲源進行到達時延差的估計;
s3、對估計後的到達時延差,結合麥克風陣列的位置構造多個雙曲面,並計算每個雙曲面的焦點,確定交互目標聲源位置,從而在交互目標聲源位置得到交互目標聲源的語音信號;
s4、預處理模塊對交互目標聲源的語音信號進行預處理,預處理包括預濾波、採樣、量化、模式轉換、預加重、加窗、分幀處理、端點檢測以及生產mfcc_d特徵參數過程;
s5、對預處理後的語音信號,聲紋密碼識別模塊提取特徵參數,將特徵參數與錄音庫的指令文本進行匹配。
進一步地,所述步驟s2中對目標聲源進行到達時延差的估計,包括在二維空間和三維空間對目標聲源進行到達時延差的估計;其中
所述二維空間對目標聲源進行到達時延差的估計,具體為:設麥克風陣列包括三個麥克風,相鄰麥克風之間的距離為δd,以陣列中心的麥克風為參考點,目標聲源距參考點的距離為r,目標聲源與距離r關係滿足下式:
式中,τ1、τ2分別是麥克風陣列兩側的兩個麥克風與參考點麥克風的時延差,v為聲速;其中,上式中表示出目標聲源相對於麥克風陣列的極坐標(r,θ)為:
由上式得,只要獲知τ1、τ2的值,即可唯一確定目標聲源的極坐標;
所述三維空間對目標聲源進行到達時延差的估計,具體為:建立麥克風陣列模型,所述麥克風陣列模型包括兩個平行的麥克風陣列,每個麥克風陣列包括三個麥克風;其中,麥克風陣列間距為d,且每個麥克風陣列均以中間的麥克風為參考點,把其中一個麥克風陣列的參考點作為原點,建立三維坐標系;設目標聲源的球坐標為根據三個麥克風均勻線陣近場信號模型中,完成目標聲源坐標中(r,θ)的確定,所以只需確定方位角即可完成目標聲源的三維定位:
首先,分別在麥克風陣列中通過上述二維空間對目標聲源進行到達時延差的估計算法,得到目標聲源相對兩個麥克風陣列參考點的極坐標(r,θ)與(r',θ'),則由陣列的幾何關係有:
其中,由上式得,給定一個方位角φ',就能由(r,θ)唯一地確定一組(r」,θ」);引入誤差函數在[-90°,90°]的範圍內遍歷方位角值,取使得誤差函數最小的為目標聲源方位角的最佳估值:
進一步地,所述步驟s2,在進行到達時延差的估計前,先對交互目標聲源進行閾值判決,具體為:
a、對交互目標聲源數據進行a/d轉換,轉換後第i個麥克風接收的信號xi(t)為:
式中,為聲音在大氣中傳播的幅度衰減因子,ri為第i個麥克風與目標聲源之間的距離,s(t)為目標聲源信號,ni(t)為包括其他說話人等幹擾源在內的各種噪聲的總和,t為時間,m為麥克風個數;
b、為了確保時延差的估計精度,對麥克風接收到的信號進行插值處理,得到xi(n);設定一個較閾值a0,根據式對xi(n)進行閾值判決處理,所述閾值a0在x′i(n)中的位置及數量目標語音信號決定,而只受少量的幹擾影響,即由x′i(n)之間的時延差可精確估計xi(t)之間的時延差;
c、對不同麥克風經過閾值判決後的信號進行相關處理,通過峰值檢測完成到達時延差的估計,所述進行相關處理方式為:
rij(τ)=e[xi(n)xj(n+τ)]。
進一步地,所述步驟c得到經過到達時延差的估計後的交互目標聲源信號,此時,需對交互目標聲源信號利用改進的加權波束形成法進行語音增強,具體為:
已知了各個麥克風與目標聲源的距離,因此通過下式對各麥克風信號進行加權:
其中ωi為對第i個麥克風信號加權的權重,ri為第i個麥克風與目標聲源之間的距離,r0為信號接收模型原點處麥克風與目標聲源的距離;
此時,麥克風陣列的輸出用下式描述:
其中,yi(n)為第i麥克風接收到的語音信號;δti為交互目標聲源信號傳播到第i個麥克風在採樣域的時間延遲;m為接收信號的麥克風數;
假設每個麥克風接收的信號具有相同的統計特性,均值都為零,功率譜為φnn(ω);經過時間補償後,各個通道的信號關於交互目標語音s(n)達到同步,則第i個麥克風經延遲補償後的信號為:
其中,是由於傳播距離造成的幅度衰減;則改進的加權波束形成法的輸出為:
由上式可知,根據目標聲源位置的遠近自適應調整通道加權的大小,不但能夠達到固定波束形成器那樣通過平均減弱噪聲幹擾的目的,同時還能最大化地利用信噪比較大通道的信號,更好地實現目標語音的增強。
進一步地,所述步驟s3中計算每個雙曲面的焦點,其具體為:
根據麥克風接收信號模型,忽略信號幅度衰減,得兩個麥克風接收的信號為:
y1(t)=s(t)+n1(t)
y2(t)=s(t-d)+n2(t)
其中,s(t)是交互目標聲源信號,d是信號到達兩個麥克風的相對時間延遲;n1(t)、n2(t)都為加性噪聲幹擾;
則y1(t),y2(t)的互相關函數r12(τ)為:
其中y1(ω)、y2(ω)分別是y1(t)、y2(t)的傅立葉變換,ψ12為廣義互相關法頻域的加權函數;根據不同的噪聲情況來選擇不同的所述加權函數,以使r12(τ)具有較尖銳的峰值。
進一步地,所述步驟s5中聲紋密碼識別模塊提取特徵參數,具體為:
s41、把一幀語音信號進行離散小波分解,分解為3層,每一層形成頻帶0khz-0.5khz、0.5khz-1khz、1khz-2khz、2khz-4khz,求出每一個頻帶的小波係數;
s42、求取每一層小波係數的頻譜和每一層小波係數fft;
s43、頻譜拼接:近似係數的頻譜直接放置在第一層;由於高通信號抽取後下變頻在低頻處產生鏡像,所有細節係數的頻譜翻轉後按照解析度由小到大拼接;如此便拼接出了整個信號的頻譜,即fft幅度譜的對稱性,後半段則是拼接後頻譜的鏡像對稱;
s44、對拼接的頻譜求取能量:通過mel濾波器組,取對數能量,經過dct變換得到特徵參數的dwt-mfc參數。
進一步地,所述步驟s5中錄音庫的指令文本,其預先通過錄音模板生產模塊進行處理,具體為:採用基於dwt-mfc的trendedhmm的模型對指令文本進行訓練:
(1)假設系統用戶a,該用戶讀3遍指定語音的文本指令,對每一遍的文本指令進行dwt-mfc特徵參數的提取,得到3個特徵向量序列;
(2)利用viterbi算法對每個特徵向量序列進行分割,將分割後的多個特徵向量序列合併為一個序列;
(3)利用sweep算法來估計模型參數;將上述的分割和優化進行迭代,直至viterbi得分進行收斂,得到每個用戶相對應的特徵參數的dwt-mfc參數。
本發明另一目的是提供一種公共背景噪聲下激活式的聲紋密碼安全控制系統,包括激活識別模塊、聲源定位拾取模塊、預處理模塊、聲紋密碼識別模塊、指令識別模塊以及錄音模板生成模塊,其中
所述激活識別模塊用於判斷接收的語音信號是否為所需要的交互目標聲源數據,從而激活聲源定位語音增強模塊;
所述聲源定位拾取模塊用於確定交互目標聲源位置,並提取語音信號;
所述預處理模塊用於對語音信號進行預處理,預處理包括預濾波、採樣、量化、模式轉換、預加重、加窗、分幀處理、端點檢測以及生產mfcc_d特徵參數過程;
所述聲紋密碼識別模塊用於對相關文本的相關說話人識別,達到雙重識別的過程;
所述指令識別模塊用于于家庭設備的命令操作;
所述錄音模板生成模塊用於預先提取用戶的聲紋密碼指令,並對聲紋密碼指令進行指令文本的訓練。
進一步地,所述聲源定位拾取模塊包括麥克風陣列,所述麥克風陣列包括若干麥克風,所述麥克風用於接收交互目標聲源數據。
採用上述技術方案後,本發明至少具有如下有益效果:
(1)本發明基於激活系統的實時檢測,保證了識別系統的非實時性,延長了識別系統的生命周期,增大了效率;
(2)本發明聲紋識別採用雙重識別,增加了安全性。
附圖說明
圖1為本發明公共背景噪聲下激活式的聲紋密碼安全控制方法的步驟流程圖;
圖2為本發明公共背景噪聲下激活式的聲紋密碼安全控制方法中對閾值判決的流程圖;
圖3為本發明公共背景噪聲下激活式的聲紋密碼安全控制方法中改進的加權波束形成法結構圖
圖4為本發明公共背景噪聲下激活式的聲紋密碼安全控制方法中對特徵參數提取步驟流程圖;
圖5為本發明公共背景噪聲下激活式的聲紋密碼安全控制系統的結構框圖;
圖6為本發明公共背景噪聲下激活式的聲紋密碼安全控制系統的麥克風陣列接收三維信號的模型圖。
具體實施方式
需要說明的是,在不衝突的情況下,本申請中的實施例及實施例中的特徵可以相互結合,下面結合附圖和具體實施例對本申請作進一步詳細說明。
如圖1所示,本發明提供一種公共背景噪聲下激活式的聲紋密碼安全控制方法,主要步驟包括:
s1、激活識別模塊在普通環境下實時進行語音信號監測,若檢測到語音信號,則對語音信號進行預加重、加窗和分幀處理,並求取語音信號的幅度值;根據實驗得到語音信號與噪聲之間的信噪比,並將信噪比轉化為幅度差t;設t為判決門限值,若語音信號的前一幀與後一幀只差大於等於t,則認為進入靜默期;若語音信號的前一幀與後一幀只差小於t,則判斷是激活標誌,並激活聲源定位拾取模塊;
s2、聲源定位拾取模塊通過麥克風陣列接收交互目標聲源數據,並對交互目標聲源進行到達時延差的估計;
s3、對估計後的到達時延差,結合麥克風陣列的位置構造多個雙曲面,並計算每個雙曲面的焦點,確定交互目標聲源位置,從而在交互目標聲源位置得到交互目標聲源的語音信號;
s4、預處理模塊對交互目標聲源的語音信號進行預處理,預處理包括預濾波、採樣、量化、模式轉換、預加重、加窗、分幀處理、端點檢測以及生產mfcc_d特徵參數過程;
s5、對預處理後的語音信號,聲紋密碼識別模塊提取特徵參數,將特徵參數與錄音庫的指令文本進行匹配。
下面為每一步驟的詳細描述。
s1、激活系統:通過實時檢測聲源定位系統得到的語音信號,從而達到激活聲紋密碼識別系統。具體步驟:第一步將語音信號進行預處理包括預加重,加窗和分幀處理。第二步進行每幀信號幅度值得求取。第三步根據實驗得到語音信號與噪聲信噪比轉化為幅度差的t設定為判決門限值,如果第二幀與第一幀之差大於t,則認為進入靜默期,第三幀與第二幀之差小於t則判斷是激活標誌,通過緩存的處理從前一幀開始進行語音信號的確定,通過判斷是否是語音信號去進行聲紋密碼系統。語音信號的確定是通過實驗所設定的語音信號的能量值去確定是否是語音信號。這樣一來,就會不輕易的啟動聲紋識別系統,降低了系統的功耗。儘可能讓系統處於休眠狀態。也防止虛檢和漏檢。
s2、聲源定位語音增強模塊:第一步:基於時延估計的聲源定位系統估計出聲源位置,具體實現步驟,第一階段,到達時延差估計,通過麥克風陣列接收的數據,估計來自交互目標聲源的信號到達陣列各個陣元的時間差;第二階段,交互目標聲源定位,利用第一階段得到的到達時延差,結合麥克風的位置構造多個雙曲面,在一定的最優準則和條件下,計算各個雙曲面焦點,確定交互目標聲源位置。具體實現過程,根據麥克風接收信號模型,忽略信號幅度衰減,得兩個麥克風接收的信號為:
y1(t)=s(t)+n1(t)(3-23)
y2(t)=s(t-d)+n2(t)(3-24)
其中,s(t)是交互目標聲源信號,d是信號到達兩個麥克風的相對時間延遲;n1(t)、n2(t)都為加性噪聲幹擾。
則y1(t),y2(t)的互相關函數r12(τ)為:
其中y1(ω)、y2(ω)分別是y1(t)、y2(t)的傅立葉變換,ψ12為廣義互相關法頻域的加權函數。加權函數比較靈活,可以根據不同的噪聲情況,選擇不同的加權函數,以使r12(τ)具有較尖銳的峰值。
廣義互相關函數法原理和結構較為簡單,基於某種最優原則在頻域對麥克風接收的信號進行加權,具有較好的抑制噪聲的能力,比較適合單聲源的時延估計。但是,廣義互相關頻域加權函數的計算需要知道聲源信號和加性噪聲的相關先驗知識,而在實際應用場景中,信號和噪聲性質是事先是無法知道的。而且,在低信噪比和有限長的觀察窗情況下,使用通過觀察的數據對加權函數的估計值代替加權函數的理論值,往往導致廣義互相關法的性能大大低於理論性能。
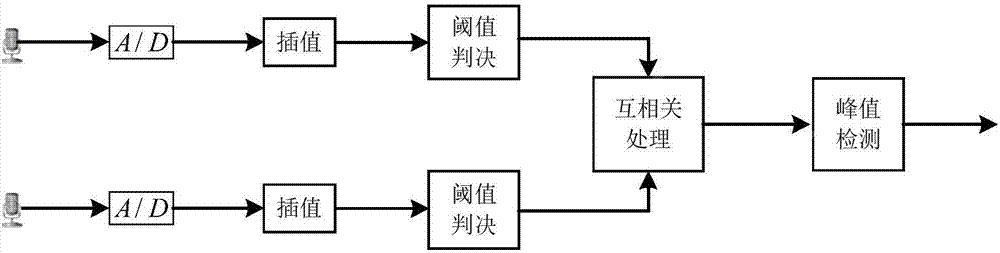
實際的人機語音交互場景主要以單目標聲源交互為主,目標語音雖然在傳播中易受環境噪聲與其他說話者的幹擾,但目標語音波形中幅度較大的信號在進行噪聲疊加時,相對變化較小,保持原有的時域特徵。則可以通過設定合適的閾值對接收的信號進行篩選,忽略小於閾值的信號,以大於閾值的信號為基準通過互相關函數估計兩信號的相對時延。基於此本文提出一種先對接收信號進行閾值判決再做相關的聲達時延差(tdoa)估計方法,算法框架如圖2所示,具體為:
麥克風陣列均勻直線陣列的近場寬接收模型中,第i個麥克風接收到的信號xi(t)為:
式中,為聲音在大氣中傳播的幅度衰減因子,第i個麥克風與目標聲源之間的距離,s(t)為目標聲源信號,ni(t)為包括其他說話人等幹擾源在內的各種噪聲的總和。
首先,為了確保時延差的估計精度,對麥克風接收到的信號進行插值處理,得到xi(n)。
然後,設定一個較大的閾值a0,根據式(3-27)對插值後的xi(n)進行閾值判決處理。由於目標語音在接收的信號中以主導的成分存在,所以在選取合適的閾值進行判決後,a0在xi'(n)中的位置及數量大都由目標語音決定,而只受少量的幹擾影響。即由xi'(n)之間的時延差可精確估計xi(t)之間的時延差。
閾值的選取極其關鍵,過小的閾值不但會增加計算量,而且在閾值判決後會殘留大量的噪聲幹擾,進而影響聲達時延差的估計,導致定位誤差的增大;而過大的閾值會導致大量的目標語音信息在閾值判決中丟失,而且易受突發強噪聲的幹擾,從而導致錯誤地估計聲達時延差。本文通過二次均值操作完成閾值a0的選取,第一次操作獲取觀察時間段內信號絕對值均值,第二次選取觀察時間段內大於信號絕對值均值的信號,並求其均值作為閾值a0的值。
最後,由式(3-28)對來自不同麥克風經過閾值判決後的信號進行相關處理,通過峰值檢測完成聲達時延差的估計。
rij(τ)=e[xi(n)xj(n+τ)](3-28)
通過閾值篩選後,幹擾噪聲信號被減弱,而目標交互語音的時延信息被保留下來。在進行相關操作估計時延時,能夠抑制噪聲的影響,大大提高時延估計的精確性。第二步:利用改進的加權波束形成法進行語音增強。具體實現步驟:已知了各個麥克風與目標聲源的距離,因此可以通過式(4-9)對各通道的信號進行加權。
其中ωi為對第i個麥克風信號加權的權重,ri為第i個麥克風與目標聲源之間的距離,r0為信號接收模型原點處麥克風與目標聲源的距離。
此時,如圖3所示,系統的輸出可用式(4-10)描述:
其中,yi(n)為第i麥克風接收到的語音信號。δti為交互目標聲源信號傳播到第i個麥克風在採樣域的時間延遲,可以通過交互目標聲源的位置信息、語音信號傳播的速度、以及採用頻率來確定,關於交互目標聲源的定位,在第三章已經做了詳細地討論。m為接收信號的麥克風數。
假設每個麥克風接收的信號具有相同的統計特性,均值都為零,功率譜為φnn(ω)。經過時間補償後,各個通道的信號關於交互目標語音s(n)達到同步,則第i個麥克風經延遲補償後的信號為:
其中,是由於傳播距離造成的幅度衰減。則改進的加權波束形成法的輸出為:
由式(4-12)可知,根據目標聲源位置的遠近自適應調整通道加權的大小,不但能夠達到固定波束形成器那樣通過平均減弱噪聲幹擾的目的,同時還能最大化地利用信噪比較大通道的信號,更好地實現目標語音的增強。
s3、聲紋密碼識別系統:此系統即相關文本的相關說話人二重識別系統。特徵參數提取步驟如圖4所示,具體步驟為:
(1)把一幀語音信號x(n)進行離散小波分解(層數為3層),形成頻帶0~0.5khz、0.5-1kh、1-2khz、2-4khz,求出每一個頻帶的小波係數。
(2)求取每一層小波係數的頻譜,每一層小波係數fft。
(3)頻譜拼接:近似係數(低頻部分)的頻譜(圖中的一半)直接放置在第一層;由於高通信號抽取後下變頻在低頻處產生鏡像,所有細節係數(高頻部分)的頻譜(圖中的一半)翻轉後按照解析度由小到大拼接;如此便拼接出了整個信號的頻譜(fft幅度譜的對稱性),後半段則是拼接後頻譜的鏡像對稱。特殊地,人耳可以聽到20hz到20khz的音頻信號,但人說話的聲音頻率範圍在300hz到3400hz。因此第一層細節係數(描述信號2-4khz)的頻譜會有一段接近零的數值,為減小計算量,把第一層細節係數頻譜的零值去掉後取前一半翻轉拼接。
(4)拼接好的頻譜求取能量,通過mel濾波器組,取對數能量,經過dct變換得到特徵參數dwt-mfc參數。
通過trendedhmm進行用戶的指令文本進行訓練得到每個用戶對應的trendedhmm,即trendedhmm就是每個用戶的指令模型。指令文本經特徵參數提取之後得到特徵向量序列,然後經過viterbi算法對每個序列進行分割。這時對模型的狀態q,得到相應的特徵向量序列。然後將此特徵向量序列與錄音庫所有用戶的模型計算viterbi得分,取得分最高的那個為識別結果。
s4:錄音庫:採用基於dwt-mfc的trendedhmm的模型進行訓練每個用戶的多遍的指令文本進行訓練。
(1)假設系統用戶a,該用戶讀3遍「開機」的指令。對每一遍的文本進行dwt-mfc特徵參數的提取。得到3個特徵向量序列。
(2)利用viterbi算法對每個序列進行分割,將多個特徵向量序列合併為一個序列。
(3)利用sweep算法來估計模型參數。將上述的分割和優化進行迭代,直至viterbi得分進行收斂。得到每個用戶相對應的模型參數。
總結:在s1的存在下推到s2再到s3,然後將s3與s4進行模板匹配。得到結果。
採樣:模擬信號首先被等間隔地取樣,這時信號在時間上就不再連續了,但在幅度上還是連續的。經過採樣處理之後,模擬信號變成了離散時間信號。一般情況下取採樣頻率為8khz。
量化:每個信號採樣的幅度以某個最小數量單位△的整數倍來度量。這時信號不僅在時間上不再連續,在幅度上也不連續了。經過量化處理之後,離散時間信號變成了數位訊號。
預加重:通過傳遞函數為h(z)=1-αz-1的高通數字濾波器來實現預加重,其中a為預加重係數,一般為0.9<a<1,設n時刻的語音採樣值為x(n),經過預加重處理後結果為y(n)=x(n)-ax(n-1),這裡取a=0.98。
加窗,分幀:進行預加重數字濾波處理後,下面就是進行加窗分幀處理,語音信號具有短時平穩性(10--30ms內可以認為語音信號近似不變),這樣就可以把語音信號分為一些短段來來進行處理,這就是分幀,語音信號的分幀是採用可移動的有限長度的窗口進行加權的方法來實現的。一般每秒的幀數約為33-100幀,視情況而定。一般的分幀方法為交疊分段的方法,前一幀和後一幀的交疊部分稱為幀移,幀移與幀長的比值一般為0-0.5。
漢明窗函數如下:
漢明窗的時域和頻域波形,窗長n=61。
根據一種公共背景噪聲下激活式的聲紋密碼安全控制方法,本發明提供了一種公共背景噪聲下激活式的聲紋密碼安全控制系統,此系統分為兩個版塊,一個是錄音版塊,另一個是語音信號識別版塊,語音信號識別版塊通過函數的調用使用錄音版塊。錄音程序在vc++環境下採用widows系統中的多媒體應用程式接口實現語音信號錄製。信號識別的過程主要是通過matlab語音仿真。做到控制及安全的統一性,高效性,安全性。本發明主要應用於要求安全係數較高的智能家居系統當中,本文主要針對門禁和保險箱兩個對安全要求較高的背景下,採用此方法。本系統主要基於安全,快速反應的語音信號識別。
本系統整體模塊如圖5所示,包括聲源定位拾取模塊、預處理模塊、激活識別模塊、聲紋密碼識別模塊、指令識別模塊以及錄音模板生成模塊,聲源定位拾取模塊包括麥克風陣列,麥克風陣列包括若干麥克風(優選為3個)。
其中,預處理模塊:預處理包括預波,採樣,量化,模式轉換,預加重,加窗,分幀處理,端點檢測,mfcc_d特徵參數。頻率為16khz,分幀處理的幀長設置為32ms,,幀移和幀長的比值為1/2,加窗為漢明窗。端點檢測採用基於能量和過零率雙重界限確定語音的起始點和結束點。
聲源定位拾取模塊:語音是人機互動中最自然的方式,既不需要接觸或佩戴數據設備,也不存在視覺盲點。在基於語音的人機互動系統中,由於噪聲的影響,特別是交互環境中其他無關說話人語音的幹擾,嚴重降低了交互系統的性能。本系統在人機互動系統語音信號信噪比的提高,可以距離式的語音操作,突破了手持式和佩戴設備對語音進行識別。本系統採用基於時延估計的聲源定位方法。
為更好地得到聲源的空間位置,基於麥克風線性均勻線陣,採用雙陣列空間三維定位的方法,提出了一種由六個數字麥克風構成的平行均勻線陣拾音模塊。結合基於閾值判決的聲達時延差估計方法實現目標聲源的三維定位。在智能家居中基於麥克風陣列聲源定位解決了噪聲抑制、混響消除、聲源測向、回聲抵消等等各個方面都得到了良好的解決。
採用matlab語言處理到的信號,使用圖6所示的平行均勻線陣三維信號接收模型,每個子陣列由3個全向數字麥克風構成,因為數字麥克風具有更好的信噪比以及更好的抗rf和emi能力。本系統將麥克風間距為15cm,陣列間距為30cm,聲音在空氣中的傳播速度定位340m/s,信號採樣頻率為16khz。通過延時疊加波束形成算法,然後通過聲源三維定位算法準確獲取目標聲源的位置信息後,通過延時補償使各通道中目標,語音信號同步後,再對各通道信號進行加權。
通過延時疊加波束形成算法得到的是目標信號的增強信號,可以通過延時疊加波束形成算法達到5db以上的增強效果。達到去噪的效果,同時也達到空間距離式的語音識別。
錄音生成模板模塊:錄音程序在vc++環境下採用widows系統中的多媒體應用程式接口實現語音信號錄製。使用多媒體應用程式接口編程簡單、控制方便。
錄音模塊有2個板塊的錄音訓練,存儲三個錄音庫,通過函數的調用來匹配相對應的語音庫。聲紋密碼語音庫:採用統計模型的隱馬爾可夫模型來描述語音模型,進行語音行庫的訓練。經過三次語音模板的錄製,提高了識別的穩定性,排除了偶然性。
激活識別系統:通過聲源定位麥克風拾取系統對聲音實時的收入語音信號,通過實時檢測的語音信號的平均幅度差(實時收入聲音的幅度與背景噪聲下的幅度的差值),當其差值達到一定的時候通過放大電路激活聲紋密碼識別模塊,背景噪聲下的幅度通過實驗來設定。
聲紋密碼模塊:此模塊是基於特定人的自有密碼設定之後的聲紋密碼識別,匹配用戶自主設定的密碼,當進入聲紋密碼識別模塊時,提示用戶說出密碼。此模塊基於模板匹配的viterb算法進行聲紋密碼識別。
指令識別模塊:此模塊主要操作門禁和保險箱的命令操作,指令內容設為「打開「,在指令識別中,本系統採用調整後的動態時間規整算法,而且dtw的時間相關性只能識別分辨指令,時間非常短,符合我們建立此系統的初衷。由於時間規整受到短時的限制,在指令識別中雖然語句是比較短的,但是動態時間規整算法還是有很多約束。為了避免因為訓練效果不好影響識別率,在使用改進後的動態時間規整的上還採用了多種路徑搜索。結果證明識別指令的識別率比較高。
儘管已經示出和描述了本發明的實施例,對於本領域的普通技術人員而言,可以理解的是,在不脫離本發明的原理和精神的情況下可以對這些實施例進行多種等效的變化、修改、替換和變型,本發明的範圍由所附權利要求及其等同範圍限定。