基於擴展局部二值模式和回歸分析的煤巖識別方法與流程
2023-12-10 07:11:42 7
本發明涉及基於擴展局部二值模式和回歸分析的煤巖識別方法,屬於圖像識別技術領域。
背景技術:
煤巖識別是指通過各種技術手段自動判別煤炭和巖石。在煤炭資源開採及運輸過程中,存在許多生產環節需要判別區分煤炭和巖石,如採煤機滾筒高度調節、綜採放頂煤過程控制、選煤廠原煤選矸等。從20世紀50年代開始,南非、澳大利亞、德國、美國、中國等世界主要產煤國家對煤巖識別方法展開了一系列研究,相繼產生了一些代表性的研究成果,如自然γ射線探測法、雷達探測法、紅外探測法、有功功率檢測法、振動信號檢測法、聲音信號檢測法等。然而這些方法均存在以下共性問題:(1)需要在現有設備上安裝部署各種傳感器,相關裝置結構複雜,製造成本高;(2)採煤機、掘進機等機械設備在煤炭生產過程中受力複雜、振動劇烈、磨損嚴重,傳感器部署相對比較困難,其電子線路也容易受到損壞,裝置可靠性差;(3)針對不同類型的機械載體設備,傳感器的選型和安裝位置的選擇存在較大區別,這就需要進行個性化定製,因此其普適性不佳。
通過對塊狀的煤炭、巖石樣本的觀察,發現煤炭和巖石在顏色、光澤、紋理等方面存在較大差異。當通過現有的數字攝像機對煤炭和巖石進行成像時,煤炭和巖石的視覺信息就必然會隱藏在採集得到的數字圖像中,因此提出通過挖掘煤巖數字圖像中的視覺信息來區分煤炭和巖石。現有的基於圖像處理的煤巖識別方法在魯棒性、識別率等方面還存在著較大的提升空間。
技術實現要素:
為了克服現有煤巖識別方法存在的不足,本發明提出基於擴展局部二值模式和回歸分析的煤巖識別方法,該方法具有實時性強、識別率高、穩健性好等優點,有助於提高現代煤礦的生產效率和安全程度。
本發明所述的煤巖識別方法採用如下技術方案實現,包括樣本訓練階段和煤巖識別階段,具體步驟如下:
rs1.在樣本訓練階段,採集m幅煤炭樣本圖像和m幅巖石樣本圖像,截取不含非煤巖背景的子圖並對它們進行灰度化處理,處理後的煤炭樣本子圖和巖石樣本子圖分別記為c1,c2,…,cm和s1,s2,…,sm;
rs2.設定採樣半徑r=2、徑向間隔δ=2、採樣鄰域數p=8和用於中值濾波的滑動窗口尺寸ωr=3×3,分別統計c1,c2,…,cm和s1,s2,…,sm的採用中值濾波並且具有旋轉不變特性和均勻特性的由基於中心點強度的描述子、基於鄰域點強度的描述子和基於徑向差分的描述子這3種描述子組合而成的魯棒擴展局部二值模式3維聯合直方圖和
rs3.分別把和形變為1維直方圖,然後對它們進行歸一化處理,得到特徵行向量α1,α2,…,αm∈r1×200和β1,β2,…,βm∈r1×200;
rs4.設定採樣半徑r=4、徑向間隔δ=2、採樣鄰域數p=8和用於中值濾波的滑動窗口尺寸ωr=5×5,分別統計c1,c2,…,cm和s1,s2,…,sm的採用中值濾波並且具有旋轉不變特性和均勻特性的由基於中心點強度的描述子、基於鄰域點強度的描述子和基於徑向差分的描述子這3種描述子組合而成的魯棒擴展局部二值模式3維聯合直方圖和
rs5.分別把和形變為1維直方圖,然後對它們進行歸一化處理,得到特徵行向量η1,η2,…,ηm∈r1×200和μ1,μ2,…,μm∈r1×200;
rs6.設定採樣半徑r=6、徑向間隔δ=2、採樣鄰域數p=8和用於中值濾波的滑動窗口尺寸ωr=7×7,分別統計c1,c2,…,cm和s1,s2,…,sm的採用中值濾波並且具有旋轉不變特性和均勻特性的由基於中心點強度的描述子、基於鄰域點強度的描述子和基於徑向差分的描述子這3種描述子組合而成的魯棒擴展局部二值模式3維聯合直方圖和
rs7.分別把和形變為1維直方圖,然後對它們進行歸一化處理,得到特徵行向量θ1,θ2,…,θm∈r1×200和
rs8.設定採樣半徑r=8、徑向間隔δ=2、採樣鄰域數p=8和用於中值濾波的滑動窗口尺寸ωr=9×9,分別統計c1,c2,…,cm和s1,s2,…,sm的採用中值濾波並且具有旋轉不變特性和均勻特性的由基於中心點強度的描述子、基於鄰域點強度的描述子和基於徑向差分的描述子這3種描述子組合而成的魯棒擴展局部二值模式3維聯合直方圖和
rs9.分別把和形變為1維直方圖,然後對它們進行歸一化處理,得到特徵行向量κ1,κ2,…,κm∈r1×200和υ1,υ2,…,υm∈r1×200;
rs10.分別構建c1,c2,…,cm和s1,s2,…,sm的原始特徵列向量x1=[α1,η1,θ1,κ1]t,x2=[α2,η2,θ2,κ2]t,…,xm=[αm,ηm,θm,κm]t∈r800×1和,…,其中t為轉置運算;
rs11.構建煤巖訓練樣本的原始特徵矩陣x=[x1,x2,…,xm,xm+1,xm+2,…,x2m]t∈r2m×800及其類別標籤矩陣y∈r2m×2,其中t為轉置運算,y的前m行第1列數據填充為1,y的前m行第2列數據填充為0,y的後m行第1列數據填充為0,y的後m行第2列數據填充為1;
rs12.設置正則化參數λ,迭代次數k和優選特徵數d,對x和y進行回歸分析,得到有利於判別煤巖的關於x的d個列標j1,j2,…,jd,其中1≤j1,j2,…,jd≤800;
rs13.先後抽取x的第j1,j2,…,jd列,然後按列排列構成煤巖訓練樣本的最終特徵矩陣其中x(col·j1),x(col·j2),…,x(col·jd)分別為x的第j1,j2,…,jd列;
rs14.在煤巖識別階段,採集未知類別樣本圖像,截取不含非煤巖背景的子圖並對它進行灰度化處理,處理後的未知類別子圖記為q;
rs15.設定採樣半徑r=2、徑向間隔δ=2、採樣鄰域數p=8和用於中值濾波的滑動窗口尺寸ωr=3×3,統計q的採用中值濾波並且具有旋轉不變特性和均勻特性的由基於中心點強度的描述子、基於鄰域點強度的描述子和基於徑向差分的描述子這3種描述子組合而成的魯棒擴展局部二值模式3維聯合直方圖hq;
rs16.把hq形變為1維直方圖,然後對它進行歸一化處理,得到特徵行向量εq∈r1×200;
rs17.設定採樣半徑r=4、徑向間隔δ=2、採樣鄰域數p=8和用於中值濾波的滑動窗口尺寸ωr=5×5,統計q的採用中值濾波並且具有旋轉不變特性和均勻特性的由基於中心點強度的描述子、基於鄰域點強度的描述子和基於徑向差分的描述子這3種描述子組合而成的魯棒擴展局部二值模式3維聯合直方圖zq;
rs18.把zq形變為1維直方圖,然後對它進行歸一化處理,得到特徵行向量ρq∈r1×200;
rs19.設定採樣半徑r=6、徑向間隔δ=2、採樣鄰域數p=8和用於中值濾波的滑動窗口尺寸ωr=7×7,統計q的採用中值濾波並且具有旋轉不變特性和均勻特性的由基於中心點強度的描述子、基於鄰域點強度的描述子和基於徑向差分的描述子這3種描述子組合而成的魯棒擴展局部二值模式3維聯合直方圖fq;
rs20.把fq形變為1維直方圖,然後對它進行歸一化處理,得到特徵行向量σq∈r1×200;
rs21.設定採樣半徑r=8、徑向間隔δ=2、採樣鄰域數p=8和用於中值濾波的滑動窗口尺寸ωr=9×9,統計q的採用中值濾波並且具有旋轉不變特性和均勻特性的由基於中心點強度的描述子、基於鄰域點強度的描述子和基於徑向差分的描述子這3種描述子組合而成的魯棒擴展局部二值模式3維聯合直方圖tq;
rs22.分別把tq形變為1維直方圖,然後對它進行歸一化處理,得到特徵行向量ξq∈r1×200;
rs23.構建q的原始特徵行向量xq=[εq,ρq,σq,ξq]∈r1×800;
rs24.先後抽取xq的第j1,j2,…,jd個元素,然後按順序排列構成q的最終特徵行向量其中xq(j1),xq(j2),…,xq(jd)分別為xq的第j1,j2,…,jd個元素;
rs25.通過計算判定q的煤巖類別,如果滿足那麼判定q為煤炭;否則,判定q為巖石,其中i為的行標,i=1,2,…,2m,j為的列標和的元素序號,j=1,2,…,d,中位於第i行第j列的元素,為的第j個元素。
步驟rs12所述的回歸分析包括以下步驟:
rs1201.構建符號矩陣u∈r2m×2,然後用1初始化u中位於前m行第1列的m個元素,用-1初始化u中位於前m行第2列的m個元素,用-1初始化u中位於後m行第1列的m個元素,用1初始化u中位於後m行第2列的m個元素;
rs1202.構建數據矩陣x0∈r2m×800,然後通過逐列初始化x0,其中τ為x0和x的列標,τ=1,2,…,800,為x0的第τ列,xτ為x的第τ列,mean(xτ)為xτ中所有元素的均值;
rs1203.分別構建權重矩陣wold,wnew∈r800×2和偏置向量bold,bnew∈r2×1;
rs1204.先通過wold=(x0)t{[x0(x0)t+λi2m]-1y}初始化wold,再通過wnew=wold初始化wnew,其中t和-1分別為轉置運算和求逆運算,i2m為2m階單位矩陣;
rs1205.構建數據矩陣lb∈r2×2m,然後通過初始化lb;
rs1206.先通過初始化bold,再通過bnew=bold初始化bnew,其中lb(col·j)為lb的第j列,j為lb的列標,j=1,2,…,2m;
rs1207.分別構建數據矩陣a,b,g∈r2m×2,然後把它們初始化為零矩陣;
rs1208.構建數據矩陣x1∈r2m×801,然後用x初始化x1的前800列,x1的第801列的所有元素均初始化為1000,即x1=[x,1000e2m]∈r2m×801,其中e2m∈r2m×1為所有元素均為1的列向量;
rs1209.定義迭代序號k1並初始化為0;
rs1210.通過更新a,其中t為轉置運算,e2m∈r2m×1為所有元素均為1的列向量;
rs1211.先通過b=u⊙a更新b,再用0替換b中的負值元素,其中⊙為矩陣的hadamard積運算;
rs1212.通過g=(u⊙b)+y更新g,其中⊙為矩陣的hadamard積運算;
rs1213.把數學描述為
的優化問題記為keyproblem,求keyproblem的解w0∈r801×2,其中||·||2,1為矩陣的l2,1–範數,以矩陣ψ∈ru0×v0為例,i0為ψ的行標,i0=1,2,…,u0,j0為ψ的列標,j0=1,2,…,v0,ψ(i0,j0)為ψ中位於第i0行第j0列的元素,u0和v0分別為ψ的行數和列數;
rs1214.用w0的前800行更新wnew;
rs1215.通過bnew=1000×[w0(row·801)]t更新bnew,其中t為轉置運算,w0(row·801)為w0的第801行;
rs1216.迭代序號k1自增1;
rs1217.若同時滿足和k1<k,則用wnew的值更新wold,用bnew的值更新bold,然後執行步驟rs1210–rs1217,其中||·||f和||·||2分別為矩陣的frobenius範數和向量的2–範數;否則,執行步驟rs1218;
rs1218.構建權重平方矩陣w2∈r800×2,然後通過w2=wnew⊙wnew初始化w2,其中⊙為矩陣的hadamard積運算;
rs1219.構建權重向量然後通過更新其中w2(col·1)和w2(col·2)分別為w2的第1列和第2列;
rs1220.完成回歸分析,返回中按從大到小順序排列的前d個元素的序號j1,j2,…,jd作為關於x的d個列標。
步驟rs1213所述keyproblem的求解包括以下步驟:
rs121301.構建數據矩陣x+∈r2m×(801+2m),然後用x1初始化x+的前801列,用2m階單位矩陣i2m初始化x+的後2m列,即x+=[x1,i2m]∈r2m×(801+2m),其中i2m為2m階單位矩陣;
rs121302.構建對角線元素向量φ∈r(801+2m)×1,然後把φ的所有元素均初始化為1;
rs121303.定義迭代序號k2並初始化為0,定義和變量sum並初始化為-1000.000;
rs121304.構建對角矩陣λ∈r(801+2m)×(801+2m);
rs121305.通過λjj=φj,j=1,2,…,(801+2m)依次更新λ的主對角線元素,其中j為φ的元素序號和λ的主對角線元素序號,φj為φ的第j個元素,λjj為λ的第j個主對角線元素,亦即λjj為λ中位於第j行第j列的元素;
rs121306.分別構建數據矩陣w0∈r801×2和w3,w4∈r(801+2m)×2,然後把它們初始化為零矩陣;
rs121307.通過更新w3,其中t和-1分別為轉置運算和求逆運算;
rs121308.用w4=w3⊙w3的計算結果更新w4,其中⊙為矩陣的hadamard積運算;
rs121309.先通過φ=w4(col·1)+w4(col·2)更新φ,若φ中存在零元素,則用0.000001替換零元素,其中w4(col·1)和w4(col·2)分別為w4的第1列和第2列;
rs121310.迭代序號k2自增1;
rs121311.若同時滿足和k2<k,則通過更新sum,然後執行步驟rs121305–rs121311,其中j為φ的元素序號,φj為φ的第j個元素;否則,執行步驟rs121312;
rs121312.用w3的前801行更新w0;
rs121313.完成keyproblem的求解,返回keyproblem的解w0。
附圖說明
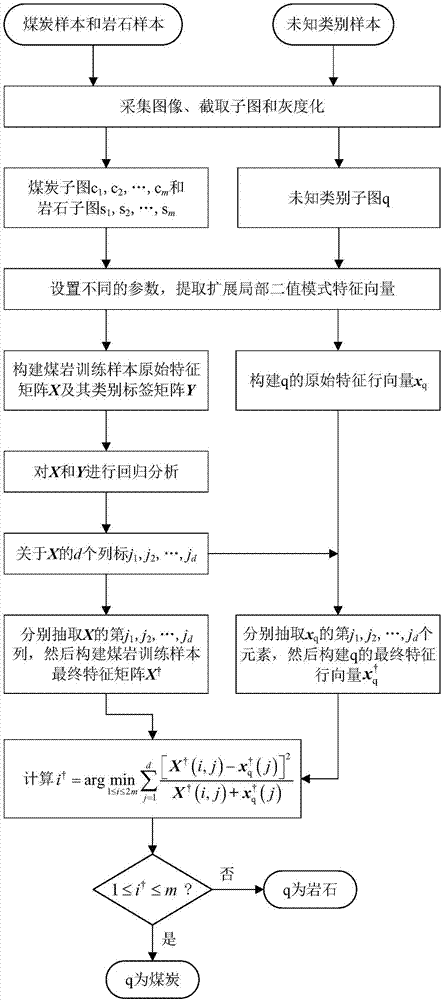
圖1是基於擴展局部二值模式和回歸分析的煤巖識別方法的基本流程圖;
圖2是本發明所述回歸分析的基本流程圖;
圖3是本發明所述求keyproblem的解w0的基本流程圖;
具體實施方式
在對我國河南、山西、陝西等地主要煤種和巖種的圖像進行實驗分析的基礎上,本發明提出了基於擴展局部二值模式和回歸分析的煤巖識別方法,該方法可以有效判別煤炭和巖石。
下面結合附圖和具體實施方式對本發明作進一步的詳細描述。
參照圖1,基於擴展局部二值模式和回歸分析的煤巖識別方法的具體步驟如下:
ss1.在樣本訓練階段,採集m幅煤炭樣本圖像和m幅巖石樣本圖像,截取不含非煤巖背景的子圖並對它們進行灰度化處理,處理後的煤炭樣本子圖和巖石樣本子圖分別記為c1,c2,…,cm和s1,s2,…,sm;
ss2.設定採樣半徑r=2、徑向間隔δ=2、採樣鄰域數p=8和用於中值濾波的滑動窗口尺寸ωr=3×3,分別統計c1,c2,…,cm和s1,s2,…,sm的採用中值濾波並且具有旋轉不變特性和均勻特性的由基於中心點強度的描述子、基於鄰域點強度的描述子和基於徑向差分的描述子這3種描述子組合而成的魯棒擴展局部二值模式3維聯合直方圖和
ss3.分別把和形變為1維直方圖,然後對它們進行歸一化處理,得到特徵行向量α1,α2,…,αm∈r1×200和β1,β2,…,βm∈r1×200;
ss4.設定採樣半徑r=4、徑向間隔δ=2、採樣鄰域數p=8和用於中值濾波的滑動窗口尺寸ωr=5×5,分別統計c1,c2,…,cm和s1,s2,…,sm的採用中值濾波並且具有旋轉不變特性和均勻特性的由基於中心點強度的描述子、基於鄰域點強度的描述子和基於徑向差分的描述子這3種描述子組合而成的魯棒擴展局部二值模式3維聯合直方圖和
ss5.分別把和形變為1維直方圖,然後對它們進行歸一化處理,得到特徵行向量η1,η2,…,ηm∈r1×200和μ1,μ2,…,μm∈r1×200;
ss6.設定採樣半徑r=6、徑向間隔δ=2、採樣鄰域數p=8和用於中值濾波的滑動窗口尺寸ωr=7×7,分別統計c1,c2,…,cm和s1,s2,…,sm的採用中值濾波並且具有旋轉不變特性和均勻特性的由基於中心點強度的描述子、基於鄰域點強度的描述子和基於徑向差分的描述子這3種描述子組合而成的魯棒擴展局部二值模式3維聯合直方圖和
ss7.分別把和形變為1維直方圖,然後對它們進行歸一化處理,得到特徵行向量θ1,θ2,…,θm∈r1×200和
ss8.設定採樣半徑r=8、徑向間隔δ=2、採樣鄰域數p=8和用於中值濾波的滑動窗口尺寸ωr=9×9,分別統計c1,c2,…,cm和s1,s2,…,sm的採用中值濾波並且具有旋轉不變特性和均勻特性的由基於中心點強度的描述子、基於鄰域點強度的描述子和基於徑向差分的描述子這3種描述子組合而成的魯棒擴展局部二值模式3維聯合直方圖和
ss9.分別把和形變為1維直方圖,然後對它們進行歸一化處理,得到特徵行向量κ1,κ2,…,κm∈r1×200和υ1,υ2,…,υm∈r1×200;
ss10.分別構建c1,c2,…,cm和s1,s2,…,sm的原始特徵列向量x1=[α1,η1,θ1,κ1]t,x2=[α2,η2,θ2,κ2]t,…,xm=[αm,ηm,θm,κm]t∈r800×1和,…,其中t為轉置運算;
ss11.構建煤巖訓練樣本的原始特徵矩陣x=[x1,x2,…,xm,xm+1,xm+2,…,x2m]t∈r2m×800及其類別標籤矩陣y∈r2m×2,其中t為轉置運算,y的前m行第1列數據填充為1,y的前m行第2列數據填充為0,y的後m行第1列數據填充為0,y的後m行第2列數據填充為1;
ss12.設置正則化參數λ,迭代次數k和優選特徵數d,對x和y進行回歸分析,得到有利於判別煤巖的關於x的d個列標j1,j2,…,jd,其中1≤j1,j2,…,jd≤800;
ss13.先後抽取x的第j1,j2,…,jd列,然後按列排列構成煤巖訓練樣本的最終特徵矩陣x(col·j2),…,x(col·jd)]∈r2m×d,其中x(col·j1),x(col·j2),…,x(col·jd)分別為x的第j1,j2,…,jd列;
ss14.在煤巖識別階段,採集未知類別樣本圖像,截取不含非煤巖背景的子圖並對它進行灰度化處理,處理後的未知類別子圖記為q;
ss15.設定採樣半徑r=2、徑向間隔δ=2、採樣鄰域數p=8和用於中值濾波的滑動窗口尺寸ωr=3×3,統計q的採用中值濾波並且具有旋轉不變特性和均勻特性的由基於中心點強度的描述子、基於鄰域點強度的描述子和基於徑向差分的描述子這3種描述子組合而成的魯棒擴展局部二值模式3維聯合直方圖hq;
ss16.把hq形變為1維直方圖,然後對它進行歸一化處理,得到特徵行向量εq∈r1×200;
ss17.設定採樣半徑r=4、徑向間隔δ=2、採樣鄰域數p=8和用於中值濾波的滑動窗口尺寸ωr=5×5,統計q的採用中值濾波並且具有旋轉不變特性和均勻特性的由基於中心點強度的描述子、基於鄰域點強度的描述子和基於徑向差分的描述子這3種描述子組合而成的魯棒擴展局部二值模式3維聯合直方圖zq;
ss18.把zq形變為1維直方圖,然後對它進行歸一化處理,得到特徵行向量ρq∈r1×200;
ss19.設定採樣半徑r=6、徑向間隔δ=2、採樣鄰域數p=8和用於中值濾波的滑動窗口尺寸ωr=7×7,統計q的採用中值濾波並且具有旋轉不變特性和均勻特性的由基於中心點強度的描述子、基於鄰域點強度的描述子和基於徑向差分的描述子這3種描述子組合而成的魯棒擴展局部二值模式3維聯合直方圖fq;
ss20.把fq形變為1維直方圖,然後對它進行歸一化處理,得到特徵行向量σq∈r1×200;
ss21.設定採樣半徑r=8、徑向間隔δ=2、採樣鄰域數p=8和用於中值濾波的滑動窗口尺寸ωr=9×9,統計q的採用中值濾波並且具有旋轉不變特性和均勻特性的由基於中心點強度的描述子、基於鄰域點強度的描述子和基於徑向差分的描述子這3種描述子組合而成的魯棒擴展局部二值模式3維聯合直方圖tq;
ss22.分別把tq形變為1維直方圖,然後對它進行歸一化處理,得到特徵行向量ξq∈r1×200;
ss23.構建q的原始特徵行向量xq=[εq,ρq,σq,ξq]∈r1×800;
ss24.先後抽取xq的第j1,j2,…,jd個元素,然後按順序排列構成q的最終特徵行向量其中xq(j1),xq(j2),…,xq(jd)分別為xq的第j1,j2,…,jd個元素;
ss25.通過計算判定q的煤巖類別,如果滿足那麼判定q為煤炭;否則,判定q為巖石,其中i為的行標,i=1,2,…,2m,j為的列標和的元素序號,j=1,2,…,d,為中位於第i行第j列的元素,為的第j個元素。
參照圖2,步驟ss12所述的回歸分析的具體步驟如下:
ss1201.構建符號矩陣u∈r2m×2,然後用1初始化u中位於前m行第1列的m個元素,用-1初始化u中位於前m行第2列的m個元素,用-1初始化u中位於後m行第1列的m個元素,用1初始化u中位於後m行第2列的m個元素;
ss1202.構建數據矩陣x0∈r2m×800,然後通過逐列初始化x0,其中τ為x0和x的列標,τ=1,2,…,800,為x0的第τ列,xτ為x的第τ列,mean(xτ)為xτ中所有元素的均值;
ss1203.分別構建權重矩陣wold,wnew∈r800×2和偏置向量bold,bnew∈r2×1;
ss1204.先通過wold=(x0)t{[x0(x0)t+λi2m]-1y}初始化wold,再通過wnew=wold初始化wnew,其中t和-1分別為轉置運算和求逆運算,i2m為2m階單位矩陣;
ss1205.構建數據矩陣lb∈r2×2m,然後通過初始化lb;
ss1206.先通過初始化bold,再通過bnew=bold初始化bnew,其中lb(col·j)為lb的第j列,j為lb的列標,j=1,2,…,2m;
ss1207.分別構建數據矩陣a,b,g∈r2m×2,然後把它們初始化為零矩陣;
ss1208.構建數據矩陣x1∈r2m×801,然後用x初始化x1的前800列,x1的第801列的所有元素均初始化為1000,即x1=[x,1000e2m]∈r2m×801,其中e2m∈r2m×1為所有元素均為1的列向量;
ss1209.定義迭代序號k1並初始化為0;
ss1210.通過更新a,其中t為轉置運算,e2m∈r2m×1為所有元素均為1的列向量;
ss1211.先通過b=u⊙a更新b,再用0替換b中的負值元素,其中⊙為矩陣的hadamard積運算;
ss1212.通過g=(u⊙b)+y更新g,其中⊙為矩陣的hadamard積運算;
ss1213.把數學描述為
的優化問題記為keyproblem,求keyproblem的解w0∈r801×2,其中||·||2,1為矩陣的l2,1–範數,以矩陣ψ∈ru0×v0為例,i0為ψ的行標,i0=1,2,…,u0,j0為ψ的列標,j0=1,2,…,v0,ψ(i0,j0)為ψ中位於第i0行第j0列的元素,u0和v0分別為ψ的行數和列數;
ss1214.用w0的前800行更新wnew;
ss1215.通過bnew=1000×[w0(row·801)]t更新bnew,其中t為轉置運算,w0(row·801)為w0的第801行;
ss1216.迭代序號k1自增1;
ss1217.若同時滿足和k1<k,則用wnew的值更新wold,用bnew的值更新bold,然後執行步驟ss1210–ss1217,其中||·||f和||·||2分別為矩陣的frobenius範數和向量的2–範數;否則,執行步驟ss1218;
ss1218.構建權重平方矩陣w2∈r800×2,然後通過w2=wnew⊙wnew初始化w2,其中⊙為矩陣的hadamard積運算;
ss1219.構建權重向量然後通過更新其中w2(col·1)和w2(col·2)分別為w2的第1列和第2列;
ss1220.完成回歸分析,返回中按從大到小順序排列的前d個元素的序號j1,j2,…,jd作為關於x的d個列標。
參照圖3,求步驟ss1213所述keyproblem的解w0的具體步驟如下:
ss121301.構建數據矩陣x+∈r2m×(801+2m),然後用x1初始化x+的前801列,用2m階單位矩陣i2m初始化x+的後2m列,即x+=[x1,i2m]∈r2m×(801+2m),其中i2m為2m階單位矩陣;
ss121302.構建對角線元素向量φ∈r(801+2m)×1,然後把φ的所有元素均初始化為1;
ss121303.定義迭代序號k2並初始化為0,定義和變量sum並初始化為-1000.000;
ss121304.構建對角矩陣λ∈r(801+2m)×(801+2m);
ss121305.通過λjj=φj,j=1,2,…,(801+2m)依次更新λ的主對角線元素,其中j為φ的元素序號和λ的主對角線元素序號,φj為φ的第j個元素,λjj為λ的第j個主對角線元素,亦即λjj為λ中位於第j行第j列的元素;
ss121306.分別構建數據矩陣w0∈r801×2和w3,w4∈r(801+2m)×2,然後把它們初始化為零矩陣;
ss121307.通過更新w3,其中t和-1分別為轉置運算和求逆運算;
ss121308.用w4=w3⊙w3的計算結果更新w4,其中⊙為矩陣的hadamard積運算;
ss121309.先通過φ=w4(col·1)+w4(col·2)更新φ,若φ中存在零元素,則用0.000001替換零元素,其中w4(col·1)和w4(col·2)分別為w4的第1列和第2列;
ss121310.迭代序號k2自增1;
ss121311.若同時滿足和k2<k,則通過更新sum,然後執行步驟ss121305–ss121311,其中j為φ的元素序號,φj為φ的第j個元素;否則,執行步驟ss121312;
ss121312.用w3的前801行更新w0;
ss121313.完成keyproblem的求解,返回keyproblem的解w0。
需要指出的是,以上所述實施實例用於進一步說明本發明,實施實例不應被視為限制本發明的範圍。