一種基於並行關聯規則挖掘的配電網運行可靠性預測方法與流程
2024-03-24 03:32:05 4
本發明涉及一種配電網運行可靠性預測方法,具體涉及一種基於並行關聯規則挖掘的配電網運行可靠性預測方法。
背景技術:
配電網運行可靠性是指涉及設備自身健康狀況、外部環境條件、系統運行條件和系統運行行為時,配電網在短期內按可接受的質量標準和所需數量不間斷地向用戶提供的電力和電量能力的度量,配電網運行可靠性預測就是通過分析計算得到配電系統在給定的時間尺度和運行條件下的可靠性指標。配電網運行可靠性評估可實現對當前系統在未來時段內的可靠性預測。目前,隨著數據採集與監控/能量管理系統(SCADA/EMS)的逐漸完善和成熟及大數據處理技術的發展,為以運行可靠性為中心的監測和調度提供了可能性。
配電網運行可靠性預測是根據運行可靠性指標評估需求,從源自各類配電系統的結構各異的各種臺帳數據、運行數據、氣象數據、社會經濟數據等海量數據中,抽取與主要評估指標相關的數據,從海量的低價值密度數據中挖掘關聯規則,尋找影響運行可靠性的主要因素,再將主要影響因素作為可行性預測的輸入,進行預測,獲得運行可靠性水平。運行可行性評估除需要大量歷史與實時數據外,由於數據量大、結構各異,難以用傳統數據處理工具進行處理。
技術實現要素:
為了克服上述現有技術的不足,本發明提供一種基於並行關聯規則挖掘的配電網運行可靠性預測方法,本發明採用並行關聯規則挖掘從海量數據中快速提取有用信息,精確定位影響可靠性指標的主要因素,減少了評估模型的輸入數據維數,簡化了建模難度。
為了實現上述發明目的,本發明採取如下技術方案:
一種基於並行關聯規則挖掘的配電網運行可靠性預測方法,所述方法包括:
(1)從多源異構配電大數據提取相關數據;
(2)用並行關聯規則挖掘方法,挖掘影響配電網可靠性的因素,建立「影響因素——>運行可靠性指標相關性模型」;
(3)根據獲取人工神經網絡的輸入影響因素,和歷史運行條件與運行可靠性參數,建立「影響因素——>運行可靠性指標定量計算模型」;
(4)將實時運行條件數據作為人工神經網絡模型的輸入,預測相應運行條件下的網絡可靠性指標值。
優選的,所述步驟(1)包括如下步驟:
步驟1-1、拼接、集成多源異構配電數據,形成包含影響因素、運行可靠性指標值的數據樣本集,記為S;
步驟1-2、T表示由多個屬性確定的每個樣本的一個「事務」,所述屬性稱為「項」,各影響因素、運行可靠性指標值分別為一個「項」;
步驟1-3、多個項組成的集合稱為「項集」,每個子集事務T都是一個項集;
步驟1-4、n個事務組成事務資料庫,根據運行可靠性指標,從樣本集中抽取可靠性指標不合格的數據樣本,組成一個事務資料庫,記為事務資料庫D。
優選的,所述步驟(1)中,所述相關數據包括網絡運行可靠性參數、條件參數以及網絡運行條件下的網絡運行可靠性指標值;所述網絡運行可靠性指標包括狀態類指標、程度類指標、層狀類指標和時限類指標。
優選的,所述類指標都包括下述子指標:潮流安全概率與裕度指標、電壓上下限安全裕度指標、潮流過載概率與期望指標、電壓越限概率與期望指標、切負荷概率指標、電力不足期望指標和電量不足期望指標;所述可靠性參數為對元件失效或停運數據進行統計分析得到的固有參數;所述條件參數為與研究的時間尺度和運行條件相關的歷史和預測數據的輸入數據。
優選的,所述步驟(2)包括如下步驟:
步驟2-1、主進程讀取事務資料庫D的過程中統計並對比各項集得到第1階候選集;
步驟2-2、用Hadoop框架下的Map函數將所述事務資料庫D劃分為部分候選集,並將其並行分發給Reduce函數,通過支持度統計並篩選出全局1階候選集,得到1階頻繁項集;
步驟2-3、根據是否存在2階候選集,確定是否生成第2階候選集,並進行數據歸類,建立「影響因素——>運行可靠性指標相關性模型」。
優選的,所述步驟2-3中,所述數據歸類包括如下步驟:
步驟2-3-1、將相同的1階頻繁項集的數據作為一類,發送到同一個MapReduce中;
步驟2-3-2、生成全局2階候選集,進而生成2階頻繁項集,以此類推,直到產生N階頻繁項集,且不存在N+1階候選集;
步驟2-3-3、輸出N個頻繁項集,獲得N個影響因素。
優選的,所述步驟(3)包括如下步驟:
步驟3-1、根據「影響因素——>運行可靠性指標相關性模型」,將數據樣本集S中的樣本提取影響因素項集,形成新的數據樣本;
步驟3-2、將所述新的數據樣本做為人工神經網絡模型的輸入,將相應的運行可靠性指標參數項集作為輸出,進行訓練;
步驟3-3、建立「影響因素——>運行可靠性指標定量計算模型」,同時及時根據最新的管理、經濟動態和新到來的信息數據,對模型進行檢驗與更新。
與最接近的現有技術比,本發明提供的技術方案具有以下優異效果:
本發明提供的技術方案採用人工神經網絡預測法,有效利用歷史數據與實時數據對網絡運行的可靠性進行準確預測,大大減少了建模難度,採用並行關聯規則挖掘從海量數據中快速提取有用信息,可以對影響網絡運行可靠性指標的主要因素進行精確定位,減少了評估模型的輸入數據維數,簡化了建模難度,實現了網絡運行可靠性的快速精確評估。
附圖說明
圖1是本發明提供的配電網運行可靠性預測模型圖
圖2是本發明提供的一種基於並行關聯規則挖掘的配電網運行可靠性預測方法的流程圖
圖3是本發明提供的並行關聯規則挖掘方法流程圖
具體實施方式
下面結合附圖對本發明作進一步詳細說明。
本發明所提的配電網運行可靠性預測是基於RTU/SCADA/EMS系統提供的大量實時運行數據,考慮設備自身健康狀況、外部環境條件、系統運行條件和系統運行行為的變化對系統可靠性的影響,研究系統在當前狀態下的短期可靠性,實時地給出系統的運行可靠性指標,基於評估結果,定量分析影響系統可靠性的關鍵因素,快速尋找系統薄弱元件和薄弱環節,保障配電網經濟可靠運行。本發明所提的預測方法是是根據運行可靠性指標評估需求,從來源於各類配電系統的結構各異的各種臺帳數據、運行數據、氣象數據、社會經濟數據等海量數據中,抽取與主要評估指標相關的數據,從海量的低價值密度數據中挖掘關聯規則,尋找影響運行可靠性的主要因素,再將主要影響因素作為可行性預測的輸入,進行預測,獲得運行可靠性水平。運行可行性評估除需要大量歷史與實時數據外,由於數據量大、結構各異,難以用傳統數據處理工具進行處理,因而,需要採用並行關聯規則挖掘與人工神經網絡預測等大數據技術。基於並行關聯規則挖掘與人工神經網絡預測的配電網運行可靠性預測模型及流程圖分別如附圖1、附圖2所示,具體步驟如下:
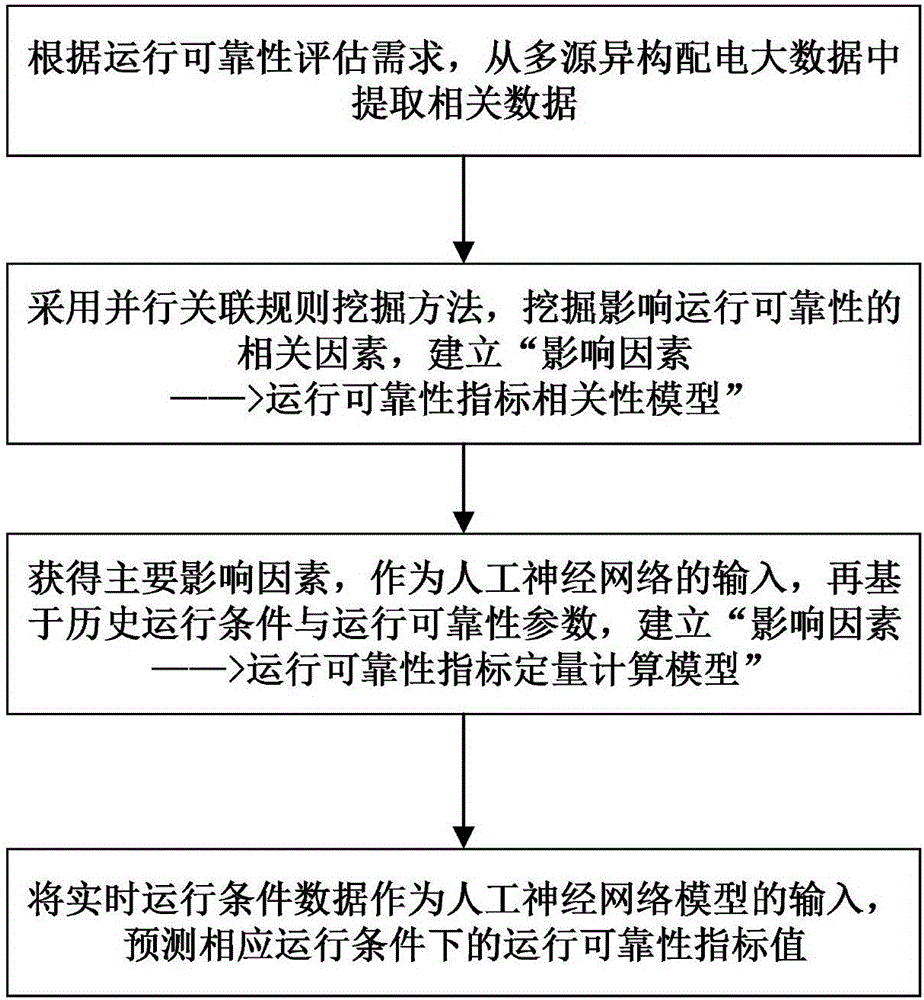
步驟1、根據運行可靠性評估需求,從多源異構配電大數據中提取相關數據;
所述多源異構配電大數據是多來源不同類型的配電數據,配電網數據源包括信息採集系統、生產管理系統、配電自動化系統、營銷系統等,類型包括結構化數據、半結構化數據和非結構化數據。
配電網運行可靠性不僅要能反映系統的負荷損失情況,還要求能反映系統的安全裕度,以及線路潮流過載、節點電壓超限等運行約束違限的情況,能夠直觀全面地描述系統整體可靠性,能夠反映重要負荷節點和關鍵元件的可靠性,能夠反映系統短期與長期的可靠性。相應的,運行可靠性指標包括狀態類指標、程度類指標、層狀類指標和時限類指標等四大類指標,各大類指標又分為若干子指標,包括:潮流安全概率與裕度、電壓上下限安全裕度、潮流過載概率與期望、電壓越限概率與期望、切負荷概率、電力不足期望、電量不足期望。配電系統的運行可靠性指標主要從現場長期運行記錄的大量統計數據中得出,運行可靠性模型需要可靠性參數和條件參數,前者是固有參數,是對元件失效或停運數據進行統計分析得到的結果,後者是輸入數據,是與研究的時間尺度和運行條件相關的歷史和預測數據,這些數據主要來源於配電系統調度、運檢、營銷、監控等業務信息,如系統運行時出現的各類信號、各類設備的狀態信息等,以及大量的經濟社會類相關數據,如地理信息、天氣、現場環境與圖像等。配電網運行可靠性數據源包括配電自動化系統、調度自動化系統、電能質量監測管理系統、生產管理系統、地理信息系統、用電信息採集系統、配變負荷監測系統、負荷控制系統、營銷業務管理系統、EPR系統、95598客服系統。
這些數據中,與運行可靠性相關的數據包括設備運行可靠性參數和條件參數,以及運行條件下的運行可靠性指標值。將這些多源異構配電數據進行拼接、集成,形成包含影響因素、運行可靠性指標值的數據樣本集,記為S,每個樣本記為一個「事務」,用T表示,每個事務由多個屬性來確定,這裡的屬性稱為「項」,各影響因素、運行可靠性指標值分別為一個「項」;多個項組成的集合稱為「項集」,每個子集事務T都是一個項集;n個事務組成事務資料庫,根據運行可靠性指標,從樣本集中抽取可靠性指標不合格的數據樣本,組成一個事務資料庫,記為事務資料庫D。
步驟2、採用並行關聯規則挖掘方法,挖掘影響運行可靠性的相關因素,建立「影響因素——>運行可靠性指標相關性模型」;
關聯規則技術在數據處理方面具有強大的處理力,採用關聯規則挖掘方法,根據運行可靠性的主要評估指標,研究各個指標與各種設備參數、電氣條件、運行狀態、環境因素等影響因素之間的相關關係,可以從海量數據中尋找到影響運行可靠性各指標相應的主要因素。運行可靠性影響因素挖掘問題中所涉及到的數據集的規模大並具有多維的特性,巨大的數據量使得關聯規則挖掘必須在多處理機上採用並行的方式處理。
關聯規則中,某子集事務T中項集A出現的頻率是包含項集的事務數,記為,也是A的支持度,大於設定的最小閥值時,A稱為頻繁項集。若項集,,且,則稱為關聯規則,事務資料庫D中包含的概率為關聯規則的支持度s,記為,支持度與置信度分別反映此關聯規則的有效性和確定性,其中支持度表徵關聯規則在事務資料庫中的重要程度或出現的概率,支持度越高,關聯程度越高。關聯規則的置信度c是包含的事務數與包含A的事務數的比值,它是概率,記做,置信度表徵關聯規則的可信程度,置信度越高,可信度越高。
在進行關聯規則挖掘之前,預先定義最小支持度閥值和最小置信度閥值,支持度大於等於最小閥值、置信度大於等於最小閥值的規則,這些規則稱為「強規則」,尋找運行可靠性指標主要影響因素的方法就是從事務資料庫D中挖掘「強規則」。關聯規則挖掘的基本過程分2個階段:①尋找事務資料庫中的所有頻繁項集;②由頻繁項集產生強關聯規則。
Apriori算法是一種常用的挖掘關聯規則的頻繁項集的方法。由於傳統的挖掘平臺自身在計算處理能力上具有局限性,傳統的數據挖掘模型不適用於多維度多噪聲的海量數據,需要採用並行挖掘模式,本發明在Hadoop框架上,將Apriori算法下MapReduce中分布實現,實現配電大數據條件下的並行關聯規則挖掘,其過程如附圖3所示,具體步驟為:
①主進程在對數據集D的讀取過程中對各項集進行統計對比,產生第1階候選集;
②利用Hadoop框架下的Map函數將D分為若干個部分候選集,再將其並行分發給Reduce函數,通過支持度進行統計並篩選出全局1階候選集,之後再產生1階頻繁項集;
③判斷是否存在2階候選集,若存在,生成第2階候選集,在生成第2階候選集後,可對數據進行一次歸類:將相同的1階頻繁項集的數據作為一類,發送到同一個MapReduce中,生成全局2階候選集,進而生成2階頻繁項集,以此類推,直到產生N階頻繁項集,且不存在N+1階候選集,輸出N個頻繁項集,獲得N個主要影響因素,建立「影響因素——>運行可靠性指標相關性模型」。
步驟3、獲得主要影響因素,作為人工神經網絡的輸入,再基於歷史運行條件與運行可靠性參數,建立「影響因素——>運行可靠性指標定量計算模型」;
根據「影響因素——>運行可靠性指標相關性模型」,將數據樣本集S中的樣本提取主要影響因素項集,形成新的數據樣本,作為人工神經網絡模型的輸入,將相應的運行可靠性指標參數項集作為輸出,進行訓練,建立「影響因素——>運行可靠性指標定量計算人工神經網絡模型」,同時及時根據最新的管理、經濟動態和新到來的信息數據,對模型進行檢驗與更新以提高預測的準確性。
步驟4、將實時運行條件數據作為人工神經網絡模型的輸入,預測相應運行條件下的運行可靠性指標值。
最後應當說明的是:以上實施例僅用以說明本發明的技術方案而非對其限制,儘管參照上述實施例對本發明進行了詳細的說明,所屬領域的普通技術人員應當理解:依然可以對本發明的具體實施方式進行修改或者等同替換,而未脫離本發明精神和範圍的任何修改或者等同替換,其均應涵蓋在本發明申請待批的權利要求範圍之內。