機器學習如何幫助Youtube實現高效轉碼?
2025-05-12 07:23:09 1
作為世界上最大的視頻平臺,YouTube 每天都會新增來自世界各地的數百萬個視頻。這些視頻具有非常大的多樣性,對 YouTube 來說,要將這些不同的視頻和相關的音頻都轉換成人們可以接受的播放質量是一個相當大的挑戰。此外,儘管谷歌的計算和存儲資源非常龐大,但也總歸是有限的, 要以上傳視頻的原格式存儲網絡視頻無疑會帶來顯著的額外成本。

為了提高網絡視頻的播放質量,關鍵是要降低視頻和音頻的壓縮損失。增加比特率是一種方法,但同時那也需要更強大的網絡連接和更高的帶寬。而 YouTube 則選擇了另一種更聰明的做法:通過優化視頻處理的參數使其在滿足最低視頻質量標準的同時不會增加額外的比特率和計算周期。
要在視頻壓縮和轉碼時滿足視頻質量、比特率和計算周期的要求,一般的做法是尋找對大量視頻(而非所有視頻)平均最優的轉碼參數組合。這種最優組合可以通過嘗試每種可能來尋找,直到找到最讓人滿意的結果。而最近,有一些公司甚至嘗試在每一段視頻上都使用這種「窮舉搜索」的方式來調整參數。
YouTube 通過在這一技術的基礎上引入機器學習而開發出了一種新的自動調整參數的方法。目前,這一技術已經在提升 YouTube 和 Google Play視頻影片的質量上得到了應用。
並行處理的優劣
據 YouTube 的博客介紹,每分鐘都有 400 小時的視頻被上傳到 YouTube 上。而其中每個視頻都需要被不同的轉碼器轉碼成幾種不同的格式,以便可以在不同的設備上進行播放。為了提高轉碼速度,讓用戶更快看到視頻,YouTube 將上傳的每一個文件都切割成被稱為「數據塊(chunk)」的片段,然後再將其每一塊都獨立地在谷歌雲計算基礎設施的 CPU 中同時進行並行處理。在這一過程中所涉及到分塊和重組是 YouTube 的視頻轉碼中的一大難題。而除了重組轉碼後數據塊的機制,保持每一段轉碼後的視頻的質量也是一個挑戰。這是因為為了儘可能快地處理,這些數據塊之間不會有重疊,而且它們會被切割得非常小——每段只有幾秒鐘。所以並行處理有提升速度和降低延遲的優勢,但它也有劣勢:缺失了前後臨近視頻塊的信息,也因此難以保證每個視頻塊在被處理後都具有看上去相同的質量。小數據塊不會給編碼器太多時間使其進入一個穩定的狀態,所以每一個編碼器在處理每一個數據塊上都略有不同。
智能並行處理
為了得到穩定的質量,可以在編碼器之間溝通同一視頻中不同分塊的信息,這樣每一個編碼器都可以根據其處理塊的前後塊進行調整。但這樣做會導致進程間通信的增加,從而提高整個系統的複雜度,並在每一個數據塊的處理中都要求額外的迭代。
但「其實,事實上我們在工程方面都很固執,我們想知道我們能將『不要讓數據塊彼此通信』的想法推進多遠。」YouTube 博客說。
下面的曲線圖展示了來自一段使用 H.264 作為編解碼器的 720p 視頻的兩個數據塊的峰值信噪比(PSNR,單位:dB每幀)。PSNR值越高,意味著圖片(視頻每幀)的質量越高;反之則圖片質量越低。可以看到每段視頻開始時的質量非常不同於結束時的質量。這不僅在平均質量上沒有達到我們的要求,這樣劇烈的質量變化也會導致惱人的搏動偽影(pulsing artifact)。
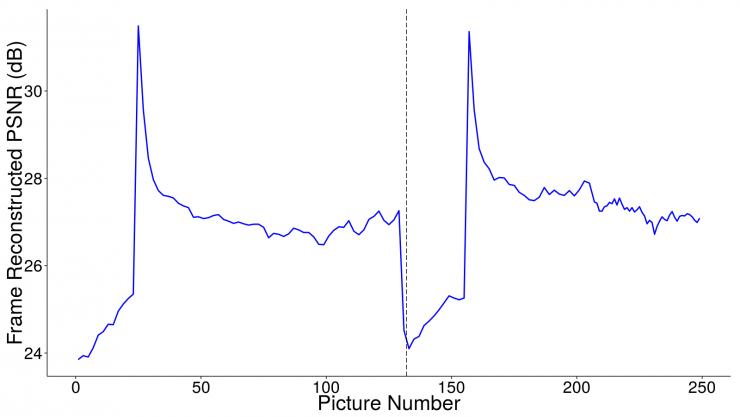
因為數據塊很小,還要讓每一塊的行為都與其前後塊的行為類似;所以研究人員需要在連續數據塊的編碼處理上保持一個大致相同的結果。儘管這在大部分情況下適用,但卻不適用於本例。一個直接的解決辦法是改變數據塊的邊界使其與高活動的視頻行為保持一致,例如快速運動或場景剪切。但這樣做就能讓保證數據塊的相對質量並使編碼後的結果更均勻嗎。事實證明這確實能有所改善,但並不能達到我們期望的程度,不穩定性仍經常存在。
關鍵是要讓編碼器多次處理每一個數據塊,並從每一次迭代中學習怎麼調整其參數以為整個數據塊中將發生的事做好準備,而非僅其中的一小部分。這將導致每一個數據塊的開端和結束擁有相似的質量,而且因為數據塊很短,所以總體上不同數據塊之間的差異也減少了。但即便如此,要實現這樣的目標,就需要很多次的重複迭代。研究人員觀察到,重複迭代的次數會受到編碼器在第一次迭代上的量化相關參數(CRF)的很大影響。更妙的是,往往存在一個「最好的」CRF 可以在保持期望質量的同時只用一次迭代就能達到目標比特率。但這個「最好的」卻會隨著每段視頻的變化而變化——這就是棘手的地方。所以只要能找到每段視頻的最好配置,就能得到一個生成期望編碼視頻的簡單方法。
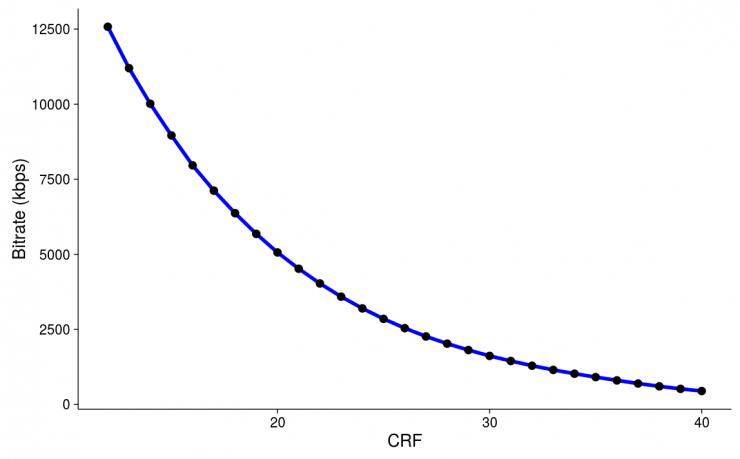
上圖展示了 YouTube 的研究人員在同一段 1080p 視頻片段上使用他們的編碼器實驗不同的 CRF 所得到的比特率結果(編碼後的視頻質量恆定)。可以看出,CRF 和比特率之間存在一個明顯的函數關係。事實上這是對使用三個參數的指數擬合的非常好的建模,而且該圖也表明建模線(藍線)與實際觀察到的數據(點)擬合得非常好。如果我們知道該線的參數,然後我們想得到一個我們的視頻片段的 5 Mbps 版本,那麼我們所需的 CRF 大約為 20.
大腦
那麼接下來需要的就是一種能夠通過對視頻片段的低複雜度的測量預測三個曲線擬合參數的方式。這是機器學習、統計學和信號處理中的經典問題。YouTube 研究人員已將其相關的數學細節發表在他們的論文中(見文末1,其中還包括研究人員想法的演化歷程)。而簡單總結來說:通過已知的關於輸入視頻片段的信息預測三個參數,並從中讀出我們所需的 CRF。其中的預測階段就是「谷歌大腦(Google Brain)」的用武之地。
前面提到的「關於輸入視頻片段的信息」被稱為視頻的「特徵(features)」。在 YouTube 研究人員的定義中,這些特徵(包括輸入比特率、輸入文件中的運動矢量位、視頻解析度和幀速率)構成了一個特徵向量。對這些特徵的測量也包括來自輸入視頻片段的非常快速的低質量轉碼(能提供更豐富的信息)。但是,每個視頻片段的特徵和曲線參數之間的確切關係實際上非常複雜,不是一個簡單的方程就能表示的。所以聰明的研究人員並不打算自己來發現這些特徵,他們轉而尋求谷歌大腦的機器學習的幫助。研究人員首先選擇了 10000 段視頻,並對其中每一段視頻的每一個質量設置都進行了嚴格的測試,並測量了每一種設置的結果比特率。然後研究人員得到了 10000 條曲線,通過測量這些曲線研究人員又得到了 4×10000 個參數。
有了這些參數,就可以從視頻片段中提取特徵了。通過這些訓練數據和特徵集合,YouTube 的機器學習系統學到了一個可以預測特徵的參數的「大腦(Brain)」配置。「實際上我們在使用大腦的同時也使用一種簡單的『回歸(regression)』技術。這兩者都優於我們現有的策略。儘管訓練大腦的過程需要相對較多的計算,但得到的系統實際上相當簡單且只需要在我們的特徵上的一點操作。那意味著生產過程中的計算負載很小。」
這種方法有效嗎?
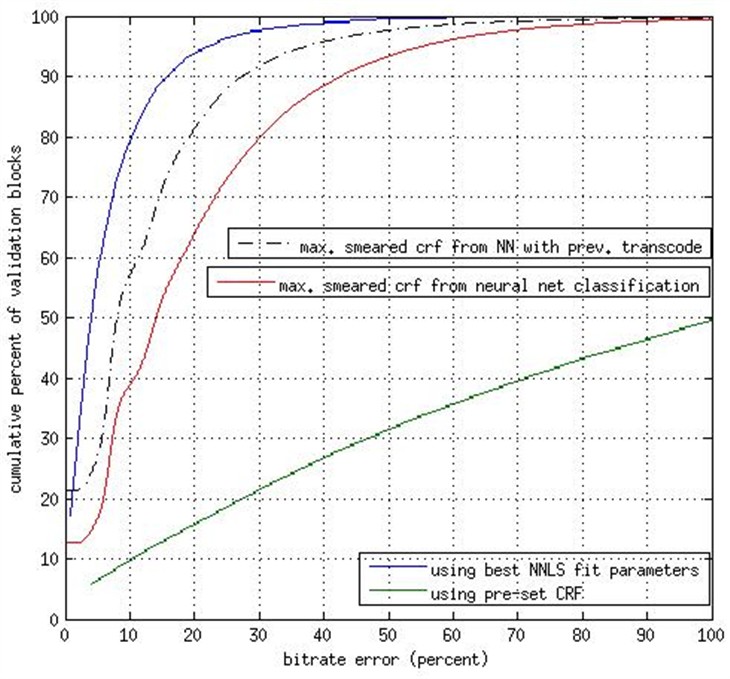
上圖展示了在 10000 個視頻片段上的各個系統的性能。其中每一個點(x,y)代表了壓縮後的結果視頻的比特率為原視頻的比特率的 x% 時的質量百分比(y 軸)。其中的藍線表示在每一個視頻片段上都使用窮舉搜索獲取完美的 CRF 所得到的最好的情況。任何接近它的系統都是好系統。可以看到,在比特率為 20% 時,舊系統(綠線)的結果視頻質量只有 15 %. 而使用了大腦系統之後,如果僅使用你所上傳的視頻的特徵,質量可以達到 65%;如果還使用一些來自非常快速低質量轉碼的特徵,更是能超過 80%(虛線)。

但是,實際上看起來如何?你可能已經注意到比起畫質,YouTube 研究人員似乎更關注比特率。因為「我們對這個問題分析表明這才是根本原因 」。畫質只有真正被看到眼裡時我們才知道好不好。下面展示了來自一段 720p 視頻的一些幀(從一輛賽車上拍攝)。上一列的兩幀來自一個典型數據塊的開始和結尾,可以看到第一幀的質量遠差於最後一幀。下一列的兩幀來自上述的新型自動剪輯適應系統處理後的同一個數據塊。兩個結果視頻的比特率為相同的 2.8 Mbps。可以看到,第一幀的質量已有了顯著的提升,最後一幀看起來也更好了。所以質量上的暫時波動消失了,片段的整體質量也得到了提升。
據悉,這一概念在 YouTube 視頻基礎設施部分的生產中已被使用了大約一年時間。YouTube的博客寫道:「我們很高興地報告:它已經幫助我們為《鐵達尼號》和最近的《007:幽靈黨》這樣的電影提供了非常好的視頻傳輸流。我們不期望任何人注意到這一點,因為他們不知道它看起來還能是什麼樣。」
參考文獻:
Optimizing transcoder quality targets using a neural network with an embedded bitrate model, Michele Covell, Martin Arjovsky, Yao-Chung Lin and Anil Kokaram, Proceedings of the Conference on Visual Information Processing and Communications 2016, San Francisco
Multipass Encoding for reducing pulsing artefacts in cloud based video transcoding, Yao-Chung Lin, Anil Kokaram and Hugh Denman, IEEE International Conference on Image Processing, pp 907-911, Quebec 2015








