不怕美國禁售!新天河推自主超算晶片
2025-05-10 20:43:26 3
天河2號再一次稱霸全球超算性能榜單(性能最大33.83PFlops,千萬億次浮點計算),雖然仍處在建設中,但它已經比較獨特的連續5次成為Top500的冠軍。

不過,高興之餘我們也有意思隱憂,因為美國商務部在今年4月份發布公告,決定拒絕英特爾公司向中國的國家超級計算中心出售至強晶片用於天河二號的升級。
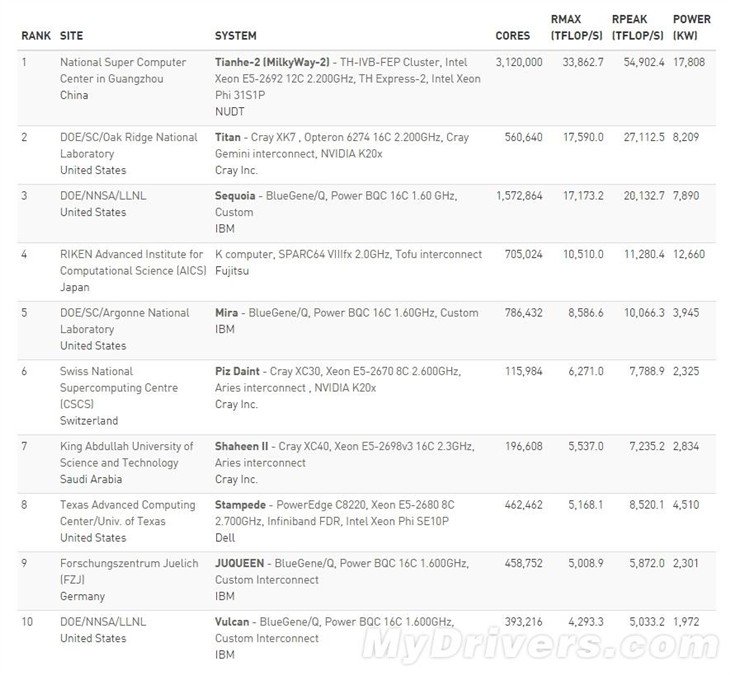
因為Xeon E5處理器比較容易獲取,所以限售的重點直指Xeon Phi計算加速卡。至於超算為什麼必須用加速卡,重點考慮的就是能耗和建設成本。
限售令公布後,天河2號系統主任設計師、國防科大教授盧宇彤曾回應,「按照原定計劃,天河二號擬在今年將計算能力從55PFLOPS升級到100PFLOPS。儘管此次美方對天河二號升級所需Intel Xeon處理器的限售,對原定升級計劃有一定影響,但我們早有準備,絕不會影響天河二號從55PFLOPS升級到100PFLOPS的既定目標 。
至於中國的信心來自那裡,本次超算峰會上,盧宇彤的主題演講也親自做了回應,我們整理了ZDnet親臨現場後發回的報導,一起來看看。

這一次,全新的天河2A首次公開對外公布了信息,和與歷代天河系統的對比,其運算峰值將達到100P,更為精彩的是,「中國計算加速卡China Accelerator」首次亮相,型號「Matrix2000」。

雖然處理器方面仍是至強E5-2692 V2,但這款自主的加速卡可謂是對「禁運令」的最大回擊。而且,在性能提升到100P的同時,天河2A的功耗幾乎沒有增加!
事實上,通用處理器在未來的HPC系統裡的權重會越來越低,主要工作將逐漸向控制層面轉移,計算任務則主要由加速器完成。因為NVIDIA GPGPU Tesla同樣在美國限售範圍內,國防科大給出的中國自主研發方案就是通用計算數位訊號處理器(GPDSP)。必須承認的是,並不算有多「高大上」。

Matrix2000的主要設計規格預計為16核設計,可達到2.4T的浮點性能,雖然還比不上Knight Landing的3T,但對於白手起家的中國來說,已經相當不易,而且功耗比現有的Xeon Phi少了100W。

Matrix2000的內部設計,採用了標量與向量單元+超長指令字(VLIW)的架構

針對全新的Matrix2000所準備的軟體堆棧,包括GPDPS驅動程序、作業系統、編譯器、數學庫等
據國防科大的相關研發人員介紹,有關DSP的浮點計算應用,一直也是國防科大的研發重點,它與超算研究可謂是並行發展。也正是因為有了這樣的積累,國防科大才能比較從容的面對美國的限售。但該研發人員也表示,GPDSP的一個推廣難點也就在於,在HPC應用領域幾乎是從零起步,就像當初NVIDIA剛推出GPGPU時一樣,直到CUDA的發布才迅速改善了GPGPU的應用生態環境。

在互聯層,採用了自主研發的TH-Express 2+架構,實現了自適應(Adaptive)互聯架構
所謂的自適應互聯架構,就從多個層面入手,通過自應用平臺層至底層形成的智能互動,保證網絡效率持續而穩定,比如自動規避質量不佳或擁擠的鏈路,進一步杜絕重複的通信,並在節點與網絡故障時對路由重新配置等等。

天河二號A仍然是以自主研發的H2FS文件系統為核心,實現了1TB/s的突發傳輸,100GB/s的持續傳輸
不過盧宇彤表示,目前Matrix2000已經通過了驗收。這意味著至少在國防科大的層面,正式投入使用已經沒有問題,但具體時間還不能確定,所以只給出了2016年這一較為籠統的時間點。
相關研發人員也透露,除了應用平臺進一步配套完善之外,GPDSP晶片本身的生產與物理設備的調優還有很多工作要做。而且受限於當前中國半導體生產工藝水平,現在還是採用40nm工藝的GPDSP,也在很大程度上制約了Matrix2000的能力。
總的來說,中國研製超大規模HPC系統的目的肯定不僅僅是為了跑個LINPACK爭個名次,否則也不會引起美國的重視並引發限售。
天河二號A的設計在某種角度上說,真正打開了中國自主HPC發展的向上之路,因為加速器很重要,也因為加速器被國外限售,所以天河二號A在這種環境下還能很快達到100P的性能,也許連美國相關人士也沒有想到,但這絕對是件好事!■








