深度學習改變世界!Deep learning簡析
2025-05-06 15:36:25 2
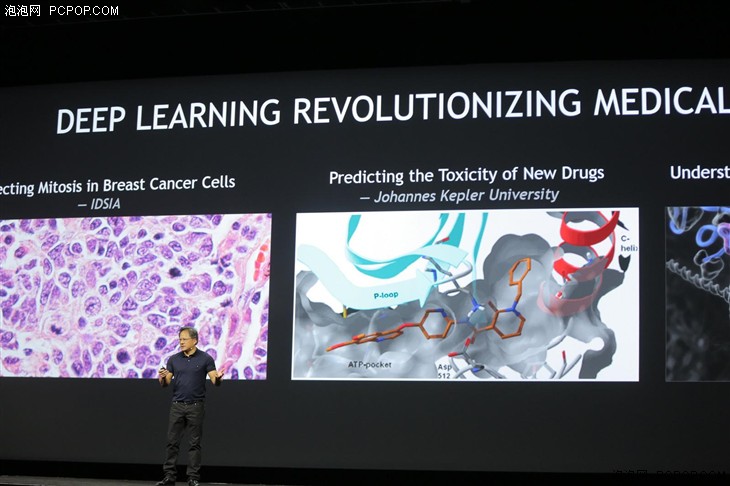
本次GTC大會上最熱的無疑就是deep learning這個詞了,NVIDIA所有新發布的產品都圍繞著它展開,而百度阿里甚至奧迪特斯拉這樣的公司也都對它產生了濃厚的興趣,似乎一夜之間,deep learning成了高新技術的代名詞,那麼它究竟是什麼來頭呢?

簡單來說,deep learning是一種機器學習的演進,可以說是大數據分析的進化版,人工智慧的前提或者說一部分。它可以解決電腦和現實的交互,也能為人工智慧提供數據支持。

deep learning的概念比較早,但真正快速發展是從2006年開始的
研究發現,人類認知過程本身就是逐層進行,逐步抽象的過程。人類首先學習簡單的概念,然後用他們去表示更抽象的,這本身就是一種層次化的組織思想和概念。

圖像聲音等等數據,電腦本身是無法理解的,所以工程師將任務分解成多個抽象層次去處理。深度學習的核心思想是把學習結構看作一個網絡,它的核心思路如下:
①無監督學習用於每一層網絡的pre-train;
②每次用無監督學習只訓練一層,將其訓練結果作為其高一層的輸入;
③用自頂而下的監督算法去調整所有層
最簡單的一種方法是利用人工神經網絡的特點,人工神經網絡(ANN)本身就是具有層次結構的系統,如果給定一個神經網絡,我們假設其輸出與輸入是相同的,然後訓練調整其參數,得到每一層中的權重,自然地,我們就得到了輸入I的幾種不同表示(每一層代表一種表示),這些表示就是特徵,在研究中可以發現,如果在原有的特徵中加入這些自動學習得到的特徵可以大大提高精確度,甚至在分類問題中比目前最好的分類算法效果還要好!這種方法稱為AutoEncoder。當然,我們還可以繼續加上一些約束條件得到新的Deep Learning方法,如如果在AutoEncoder的基礎上加上L1的Regularity限制(L1主要是約束每一層中的節點中大部分都要為0,只有少數不為0,這就是Sparse名字的來源),我們就可以得到Sparse AutoEncoder方法。

當然,還有其它的一些Deep Learning 方法。總之,Deep Learning能夠自動地學習出數據的另外一種表示方法,這種表示可以作為特徵加入原有問題的特徵集合中,從而可以提高學習方法的效果。
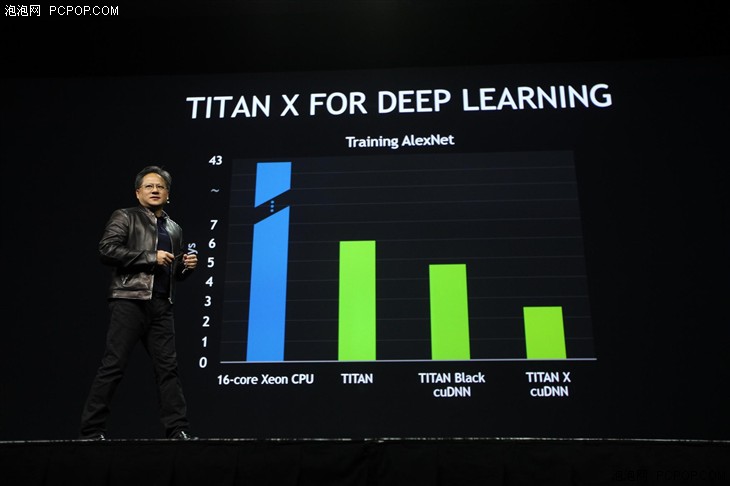
TITAN X強大的並行運算能力讓deep learning變得更加容易
每個數據樣本要拆成十幾二十層來分析,所以deep learning雖然很美,卻需要強大的算力保證,據悉目前包括百度谷歌微軟在內的很多公司都花了大力氣投入deep learning的研發,而傳統經營超算的公司如曙光和浪潮他們的伺服器已經有很多時間開始deep learning的運算了。因為有了deep learning,智能駕駛,智能人機互動在不遠的未來都將成為現實,但前者的用途顯然不止於此,未來前景不可估量。■









