順豐科技 x StarRocks:雙十一實時運單分析實踐
2025-05-03 21:53:25 2
順豐科技有限公司隸屬於順豐速運集團,成立於2009年,致力於構建智慧大腦,建設智慧物流服務。順豐科技經過多年的自主研發,已經建成大數據整體生態系統,完成數據採集與同步、數據存儲與整合、數據分析與挖掘、機器學習、數據可視化等平臺的構建。在建設底盤平臺的基礎上,結合大數據、區塊鏈、物聯網與人工智慧技術,廣泛應用於速運、倉儲、冷運、醫藥、商業、金融、國際等業務領域。
順豐大數據平臺簡介
早期順豐在OLAP層主要使用了Elasticsearch、ClickHouse、Presto、Kylin這四個組件。
Elasticsearch在順豐場景使用的最多,倒排索引的機制下,檢索效率高,整體運維也比較方便。目前在日誌類、條件檢索類的場景用的比較多。目前版本以Elasticsearch 5.4為主,新接入的業務使用了7.6版本,基於標準版本進行了一些定製化的開發工作,包含跨機房備份方案、K8S容器化部署、數據服務平臺等。
ClickHouse是這兩年引入,用於一些重點的運單場景,進行了K8S集群化改造,很好的滿足了資源快速交付的需求。
Presto在順豐也使用的很多,主要用於Hive數據的查詢。我們針對Presto進行了Yarn集群部署的改造,很好地用到了Yarn隊列的資源。
Kylin使用的相對較少,目前只在財經線的幾個業務上作為試點。
當前痛點及產品選型
順豐通過內部容器化建設、組件深度定製、組件平臺的建設,組件的一些突出問題、共性問題已經解決,但是還有一些難以解決的組件自身的痛點問題。我們對這些組件的問題進行了一些總結:
一、多版本多框架並存、基礎組件升級難。由於歷史原因,同時存在多個版本在線上運行,但因為多個版本的不兼容性,用戶業務在線上穩定運轉,主動切換意願不高,導致版本難以統一,組件升級方案複雜、操作風險高,也是組件升級難的另外一方面原因。
二、用戶選用組件容易一刀切。在實際的應用中,有很多用戶進行大數據選型時,缺乏對組件本身的了解,導致大量的使用不合理的情況,如使用ES做大量的聚合計算、使用Presto做報表、使用Kafka做批量交互等。
三、使用難/運維難。各種組件的使用/運維不盡相同,需要用戶和運維都要具備相應的專業知識。

OLAP產品選型
目前OLAP場景,各家百花齊放。可以選擇的組件很多,選擇合適的組件需要方法論的支持。目前我們順豐在選型上,遵照了以下原則:
·組件的核心能力要夠強,短板不明顯。
·組件交付的版本工程質量高。
·核心訴求/大的生產環境的問題響應足夠及時。
·可塑性強,未來長期發展潛力大。
·運維的門檻要低。
我們針對性進行了相應的評估,評估包含下面一些方面:
·不同產品之間使用標準測試集的橫向評估,主要選取評估的組件有ClickHouse、Presto、Apache Doris、StarRocks。
·中等業務規模的業務體驗:10億規模的契合度高的場景,帶Join。
·公司內典型場景的需求評測:百億規模的運單場景的典型SQL等。
·重點功能項的評測:如大數據數據導入、大表Join、failover等。
從評估的結果來看,對於StarRocks我們整體還是比較滿意的,最終我們選擇了StarRocks,基於如下的考慮:現階段StarRocks性能、穩定性佔優;StarRocks處於高速發展期,能夠提供專業的技術支持、生產環境問題/需求的快速反應;StarRocks擁有強大的運維管理系統,用戶開發、運維的功能很全面。
StarRocks應用實踐
整體目標
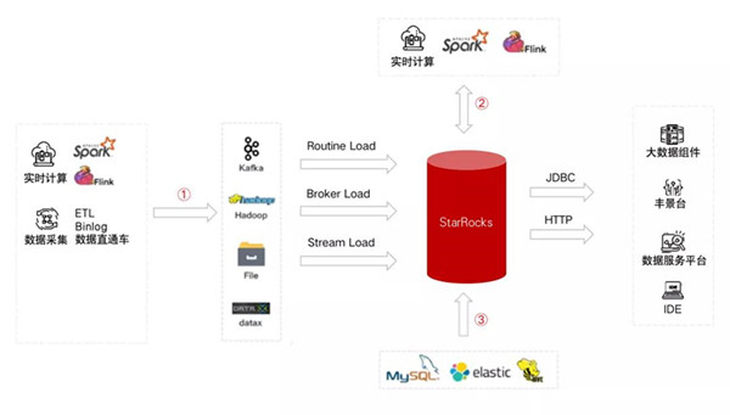
順豐引入StarRocks的目標是:使StarRocks成為一站式的大數據分析平臺的底座。從數據的源頭來看,包含三條數據流:
·實時數據、離線數據導入,通過StarRocks原生的幾種Load任務完成。
·通過Flink/Spark的Connector完成數據ETL。
·Hadoop、Elasticsearch、MySQL等環境中的數據,作為數據源,通過StarRocks外表導入。
從數據使用的角度來看,通過JDBC接口給數據使用者提供服務,主要的數據使用者包含:
·組件開發/組件維護,目前順豐環境對應的是大數據組件平臺。
·BI工具平臺,在順豐內部叫作豐景臺。
·數據中臺,如數據服務、數據字典等。
·業務平臺的訪問,比如數據平臺臨時查詢導數的平臺,及其他一些業務平臺。
為了應對統一的大數據分析底盤的訴求,需要一些場景化的能力,這裡列一些我們主要的訴求:
·替代Presto,在BI工具平臺快速查詢Hive數據。
·替代ElastcSearch、ClickHouse、Kylin做OLAP明細、匯總數據的存儲。
·較好的數據導出能力,便於業務做二次分析。
StarRocks應用進展
業務接入
·運單級別的業務已經完成開發,正在灰度運營中。
·其他幾個細分業務領域也完成了接入,如財務、快運、國際等。
·其他也有一些業務正在接入、體驗中。受限於前期的機器採購預算未申報,接入節奏不算快。
統一的OLAP平臺能力建設
·已經可以進行BI工具平臺打通。
·全鏈路的多個集群環境的搭建,包含測試集群/預發布集群/生產公共集群/容災公共集群/重點業務私有集群。
·大數據平臺DataX集成、Flink/Spark Connector的集成正在開發/測試中。
·中臺的數據服務、數據字典等正在進行相關的設計,目前也和鼎石團隊在一起看如何拿到元數據。
實踐案例
在物流行業,運單場景是最典型的場景。這裡給大家分享一個順豐最大體量級別的運單場景。這個場景原來是在Oracle上單機運行,更新頻繁、對時效要求高。業務上存在著許多的痛點,業務數據成倍增長導致原來系統已經不堪負荷,主要表現為可用性不高、速度變慢、數據多份、時效性不高等。業務側的訴求是希望接入StarRocks以後,性能和時效性大幅度提升,能夠在現有業務翻倍雙11場景下的撐得住,提供高可用的方案,能夠快速擴容等等。
需求澄清
接到這個任務後,我們梳理了一遍需求:
·硬性指標,雙11要滿足單行數據2k左右大寬表、8萬TPS寫入訴求。
·業務峰值效應明細,未來還會有大的增長空間。
·數據保存三個月以內的數據,目前數據量在百億級別以內。
·舊業務改造需要考慮已有BI平臺工具的2K+報表的平滑過渡。
·數據導出需求,供業務側做二次分析。
數據導入
針對需求,我們做了數據導入和查詢兩個方面的方案設計和優化。從數據導入來看,核心問題是提升單機數據寫入性能。
·表設計按照日期分區,按照運單號分桶,第一個問題就是如何進行數據分布的設計,從使用經驗來看,Kafka分區個數與StarRocks的BE節點個數、導數任務並行度要一致,導入效率才最高。
·由於源頭數據來源於不同的業務系統加工成大寬表,需要通過配置欄位的replace_if_not_null支持部分欄位更新,另外為了避免Json數據欄位增刪導致導數失敗,需要每個欄位指定Json位置。
·StarRocks導入能力與單條記錄的字節數、合併效率有很大關係。為了更高的導入性能,我們把大寬表的按列分拆為兩個,更新少的數據放入一個表(這裡叫公表)、更新頻繁的放到另外一個表(私表),多表的導入的任務數會增加。
·機器選型上,由於寫入頻繁,我們升級了單機6盤到12盤,未來考慮使用ssd;StarRocks向量化優化深入,我們升級了40核到80核,提升QPS。
·系統按照日期進行分區,由於數據來源於多個業務系統,存在分區時間沒有的情況,需要反查,初期方案是從StarRocks跨區查,效率較低,後面採用了Flink的RocksDB方案。
·跨機器跨磁碟的副本均衡問題:由於機器down機或者增刪磁碟造成的,目前跨機器的副本均衡已經在最新版本解決,跨磁碟的副本均衡期待在後續版本解決。
·版本數問題:如果版本數過多會導致BE節點暫停從Kafka消費,導致數據導入效率下降。這裡可以通過調整Kafka消費時間、合理設置分片、分區個數、副本個數減少版本數。
查詢
·為解決原有系統的2K+報表的平滑遷移問題,由於拆成了兩個表,新增加了一個視圖,保持跟原有表結構一致,降低遷移成本。
·跟BI平臺合作,做了一些查詢並行度限制核數據緩存策略,提高系統的穩定性。
為了提高的查詢性能,做了一些針對性的優化工作:
·對於最常用的查詢條件欄位,加到key列,如客戶的公司等。
·通過增加布隆過濾器索引提升查詢效率。
·大表間的Join,調整Join的順序(未開啟CBO)。
·兩表Join時,增加冗餘欄位並放在ON條件裡面使條件能夠下推,減少掃描量。
·問題:為了提升查詢性能,將查詢條件中的非key列的加到了key列,對於此非key列的變更變成了刪除+插入兩步操作,可能會造成未合併的版本數累積。

目前系統的整體數據來源於多個業務系統,通過Flink進行計算後寫入一個新的Kafka,StarRock通過Routine Load從新的Kafka拉取數據,很好的實現了Exactly Once語義,各個系統的耦合度很低,可用度高。
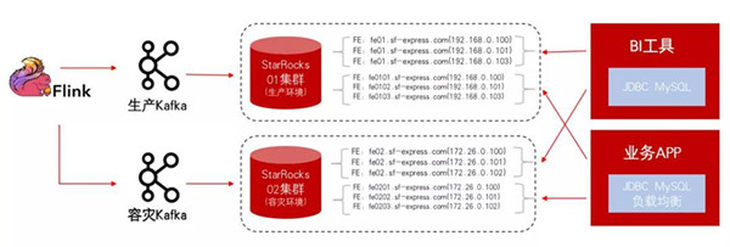
為了更高的可用性,我們採用了雙機房、雙寫、雙活的方案。通過兩種域名配置方式以負載均衡方式給BI工具和業務APP使用。業務APP通過域名、JDBC LB方案具有更高可用性,機器遷移、down機無影響。
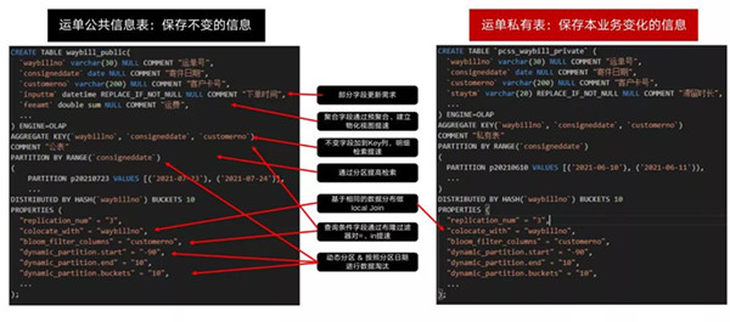
這裡是我們具體的表設計:
1)聚合表模型、同時支持明細表和物化視圖。
2)按照使用更新頻度分成兩個表,提高導入任務個數。
3)按照寄件日期分區,運單號分桶。
4)通過replace_if_not_null支持部分欄位更新。
5)變化不頻繁欄位加到key列,並兩個表冗餘,提高查詢效率。
6)兩表按照CollocateJoin提升Join效率。
7)按照日期動態分區,支持數據淘汰。
8)查詢條件增加布隆過濾器索引,提升檢索效率。

在適應性更高的場景、如不更新、數據量10億以下等,StarRocks更加得心應手,性能強大。這裡是目前順豐接入的其他一些非運單明細的場景,StarRocks都有良好表現,如原財務系統,時常會出現告警。接入StarRocks以後,使用1/3的資源消耗即可良好的運行。
後續規劃和社區共建
我們後續在OLAP方面的規劃如下:
·ClickHouse的新業務接入已基本停止。
·明年準備大規模接入StarRocks,已經全面啟動相關的機器採購預算申請,運單級別的業務系統已經有幾個規劃會進行改造接入。
·另外在雲上數倉項目上,期待繼續深入使用StarRocks。
目前StarRocks已經原始碼開放,面向未來,StarRocks有更多的可能性。順豐也有基於StarRocks建設統一、全場景、極速OLAP分析平臺的訴求:
·從終端用戶來看:建設一站式的開發/運營平臺。
·從資源管理來看:達到serverless的管理目標、可衡量。
·從運維層面來看:更高可用性、更多的工具。
·從數據模型來看:更多的場景化模型支持。
·從統一查詢平臺:各種資料庫引擎的更好支持。
·從生態來看:深入各個周邊場景提供更多能力。
我們願意與StarRocks社區一起,攜手共進,為社區貢獻我們的一份力量。(作者:嚴向東,順豐科技大數據平臺架構師)
